Checking domain availability with AWS Route 53 - Part 2
Part 2: Converting TLD Provider into an API
In all fairness, this part is not entirely necessary for the project. I already found a way to get the list of TLDs from Amazon documentation so I could easily integrate it with my client applications. But I recently heard about Amazon API Gateway which has been introduced a few weeks back so I thought it would be cool to access my JavaScript method via a web API hosted on AWS. After all, the point of many projects I develop is to learn new stuff! In light of that I’ll try something new with the C# version as well and use a self-hosted service so that I can use a Windows Service instead of IIS.
API #1: Amazon API Gateway
There are a couple of new technologies here that I haven’t used before so this was a good chance for me to play with them.
Amazon API Gateway looks like a great service to create hosted APIs. Also it’s integrated with AWS Lambda. You can bind an endpoint directly to lambda function. There are other binding options but in this project I will use Lambda as it was also in my to-learn list.
Setup Amazon API Gateway
API Gateway interface is very intuitive. Within minutes I was able to create a GET method calling my Lambda function. First you create the API by clicking the “Create API” button!
Then you add your resource by clicking “Create Resource”. By default it comes with the root resource (“/”) so you can just use that one as well to add methods.
I created a resource called tldlist. All I needed was a GET method so I created it by “Create Method”.
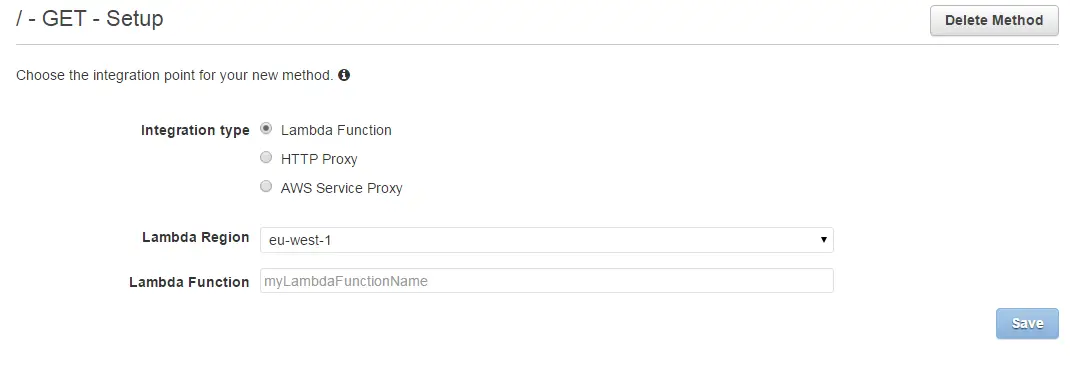
You select the region and enter the full ARN of your Lambda function. In the UI it just says “function name” but it requires full ARN (i.e.: arn:aws:lambda:eu-west-1:1234567890:function:getTldList)
…and Lambda
The function is a bit different from the previous version. In Node.js I wasn’t able to use XMLHttpRequest object and turns out your use the http module to make web requests so I modified the code a bit. Here’s the final version of my Lambda function:
console.log('Loading function');
var docHost = 'docs.aws.amazon.com';
var docPath = '/Route53/latest/DeveloperGuide/registrar-tld-list.html';
var supportedTldPage = docHost + docPath;
var http = require('http');
exports.handler = function(event, context) {
var options = {
host: docHost,
path: docPath,
port: 80
};
http.get(options, function(res) {
var body = '';
res.on('data', function(chunk) {
body += chunk;
});
res.on('end', function() {
console.log(body);
var result = parseHtml(body);
context.succeed(result);
});
}).on('error', function(e) {
console.log("Got error: " + e.message);
});
};
function parseHtml(pageHtml) {
var pattern = /<a class="xref" href="registrar-tld-list.html#.+?">[.](.+?)<\/a>/g;
var regEx = new RegExp(pattern);
var result = {};
result.url = 'http://' + supportedTldPage;
result.date = new Date().toUTCString();
result.tldList = [];
while ((match = regEx.exec(pageHtml)) !== null) {
result.tldList.push(match[1]);
}
return result;
}
In order to return a value from Lambda function you have to call succeed, fail or done:
context.succeed (Object result);
context.fail (Error error);
context.done (Error error, Object result);
Succeed and fail are self-explanatory. done is like a combination of both. If error is non-null it treats it as failure. Even if you call fail or done with an error the HTTP response code is always 200. what changes is the message body. For example, I played around with a few possibilities to test various results:
Method call: context.succeed(result);
Output: Full JSON results
Method call: context.done(null, result);
Output: Full JSON results
Method call: context.fail("FAIL!!!");
Output: {"errorMessage":"FAIL!!!"}
Method call: context.done("FAIL!!!", results);
Output: {"errorMessage":"FAIL!!!"}
As you can see, if error parameter is not null it ignores the actual results. Also I removed the JSON.stringify call from the parseHtml method because API gateway automatically converts it to JSON.
Tying things together
Deployment is also a breeze, just like creating the API, resource and the methods all it takes is a few button clicks. You click Deploy API and create an environment such as staging or prod. And that’s it! You’re good to go!
Since this will be a public-facing API with no authentication I also added a CloudWatch alarm:
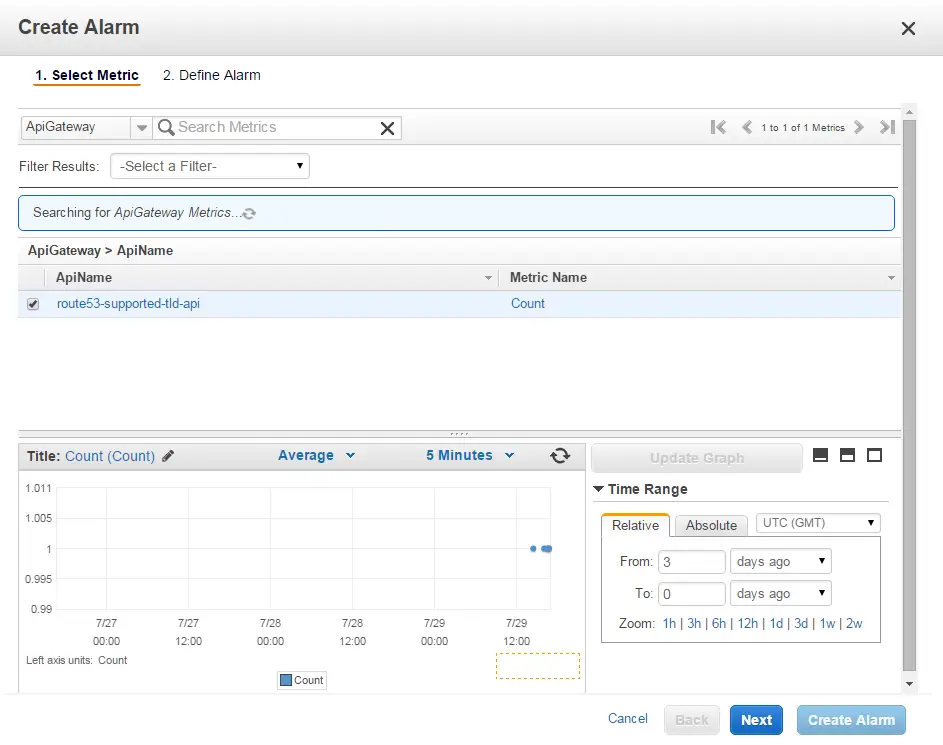
This way if some mental decides to abuse I will be aware of it. The good thing is it’s very cheap. It costs $3.5 per million API calls which is about £2.25. I don’t think it will break the bank but for serious applications authorization is a must so I will need to investigate that feature in the future anyway.
At this point, I have a Lambda function called from the API hosted by AWS. I don’t have to worry about anything regarding the maintenance and scaling which feels great!
API #2: C# & Self-hosting on a Windows Service
Speaking of maintenance, here comes the Windows version! I don’t intend to deploy it on production but I was meaning to learn self-hosting APIs with Web API to avoid IIS and here’s chance to do so.
Found this nice concise article showing how to run a Web API inside a console application. I tweaked the code a little bit to suit my needs. Basically it takes 4 simple steps:
Step 01. Install OWIN Self-Host NuGet package:
Install-Package Microsoft.AspNet.WebApi.OwinSelfHost
Step 02. Setup routing
public class Startup
{
public void Configuration(IAppBuilder appBuilder)
{
HttpConfiguration config = new HttpConfiguration();
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new { id = RouteParameter.Optional }
);
appBuilder.UseWebApi(config);
}
}
Step 03. Add the controller
public class TldController : ApiController
{
public HttpResponseMessage Get()
{
string supportedTLDPage = ConfigurationManager.AppSettings["AWS-URL"];
var tldProvider = new TldListProvider();
var tldList = tldProvider.GetSupportedTldList(supportedTLDPage);
var output = new {
url = supportedTLDPage,
date = DateTime.UtcNow.ToString(),
tldList = tldList.Select(tld => tld.Name)
};
return this.Request.CreateResponse(HttpStatusCode.OK, output);
}
}
Step 04. Start OWIN WebApp
public void Start()
{
string baseAddress = ConfigurationManager.AppSettings["BaseAddress"];
WebApp.Start<Startup>(url: baseAddress);
Console.WriteLine("Service started");
}
Final step is installation. As I used TopShelf all I had to do was running a command prompt with administrator privileges run this command:
TldProvider.Service.exe install
Now that my service is running in the background and accepting HTTP requests let’s take it out for a spin:
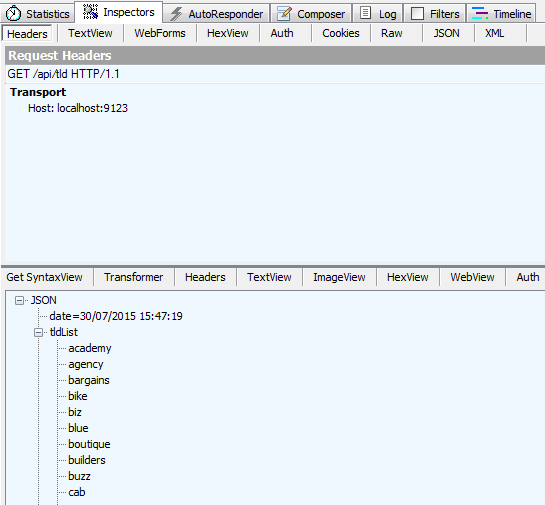
Brilliant!
What’s next?
So now I have an API that returns me the supported TLD list. In the next post I’ll work on a basic client that consumes that API and AWS Route53 to get the availability results finally.