Customizing phone with NFC Task Launcher
If you have an Android phone that supports NFC, you can save and change some settings very easily based on your location. All you need is some blank NFC tags like shown below, which are very cheap and a free app called NFC Task Launcher.

NFC for the uninitiated
NFC stands for Near Field Communication. It’s a set of standards build on RFID that allows wireless communication between devices in a close proximity. It is commonly used in contactless payment systems.
Manage tasks with the task launcher
It’s a very intuitive and easy to use app. First, you select an action group (like WiFi On/Off, BlueTooth On/Off).
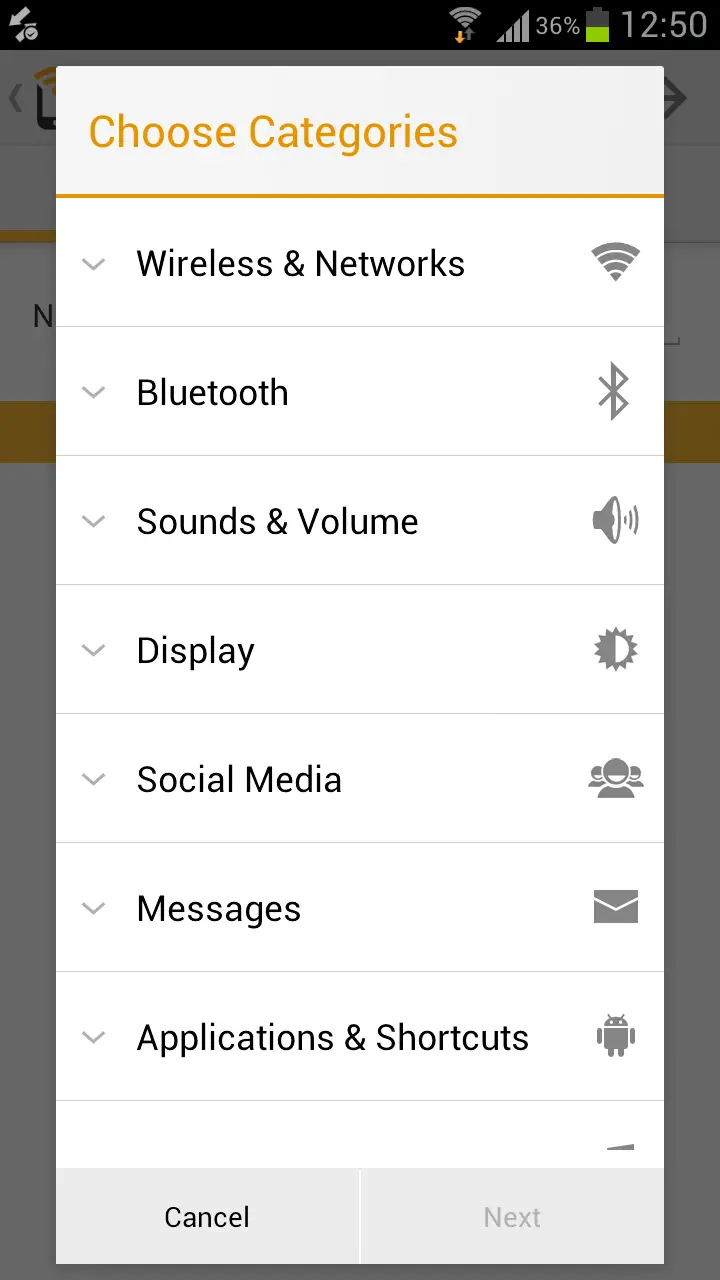
Then you configure the action (like Enable/Disable) and finally you touch to your tag to associate the task with it.
Secure your phone outside the house
After playing around with tools like WiFi PineApple I’m now even more afraid of wireless networks than ever. Thinking about it, I don’t connect to open networks on purpose and if my phone connects to one of them that means something fishy is going on. So why should I have WiFi when I’m not using my own? But of course turning it on and off every time I enter/leave the house is cumbersome. My solution is: doing it with NFC. Although it’s not completely automated, I just touch my phone to the red tag I stuck to my door when I leave the house and the WiFi is turned off. When I enter the house, I touch on the green one it is turned back on. Simple as that!