When moving to a new machine, re-installing all the applications is sounds a very daunting task. Linux distros have been enjoying the ease of package repositories for quite a long time and users can install almost everything they need by package manager applications like apt-get and yum. Chocolatey aims to bring the same convenience to Windows.
Easy Install Indeed!
Installation is a breeze as shown in their website. By using some Powershell and NuGet magic you download a script which then downloads Chocolatey package from the repository. You may have noticed the URL is very similar to nuget.org’s package path. That’s simply because it uses NuGet under the hood. Even the user interface is just a skinned version of NuGet Gallery (which is open source and can be downloaded from GitHub).
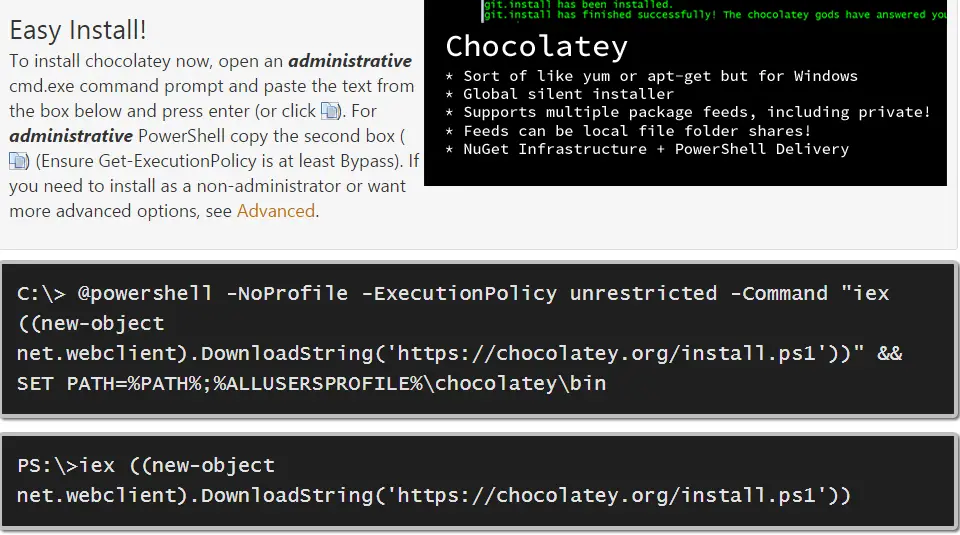
Automate all installations
After Chocolatey is installed all you have to do is browse the packages and select the ones you want to install with an easy command such as:
choco install atom
And after a bunch of colourful messages you’re good to go.
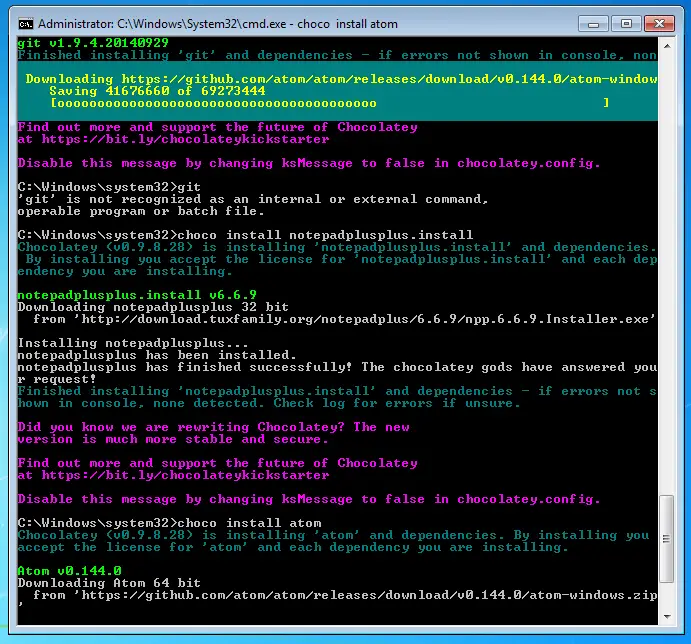
Are we done?
Most core tools for development and everyday use (SysInternals, Fiddler, Chrome, FireFox, NodeJS, Python, VLC, Paint.NET etc.) can be installed automatically using Chocolatey. The major applications such as Visual Studio and SQL Server still need some love and your caring hands but I think automating installation of tens of applications in such an easy way is priceless.
Resources