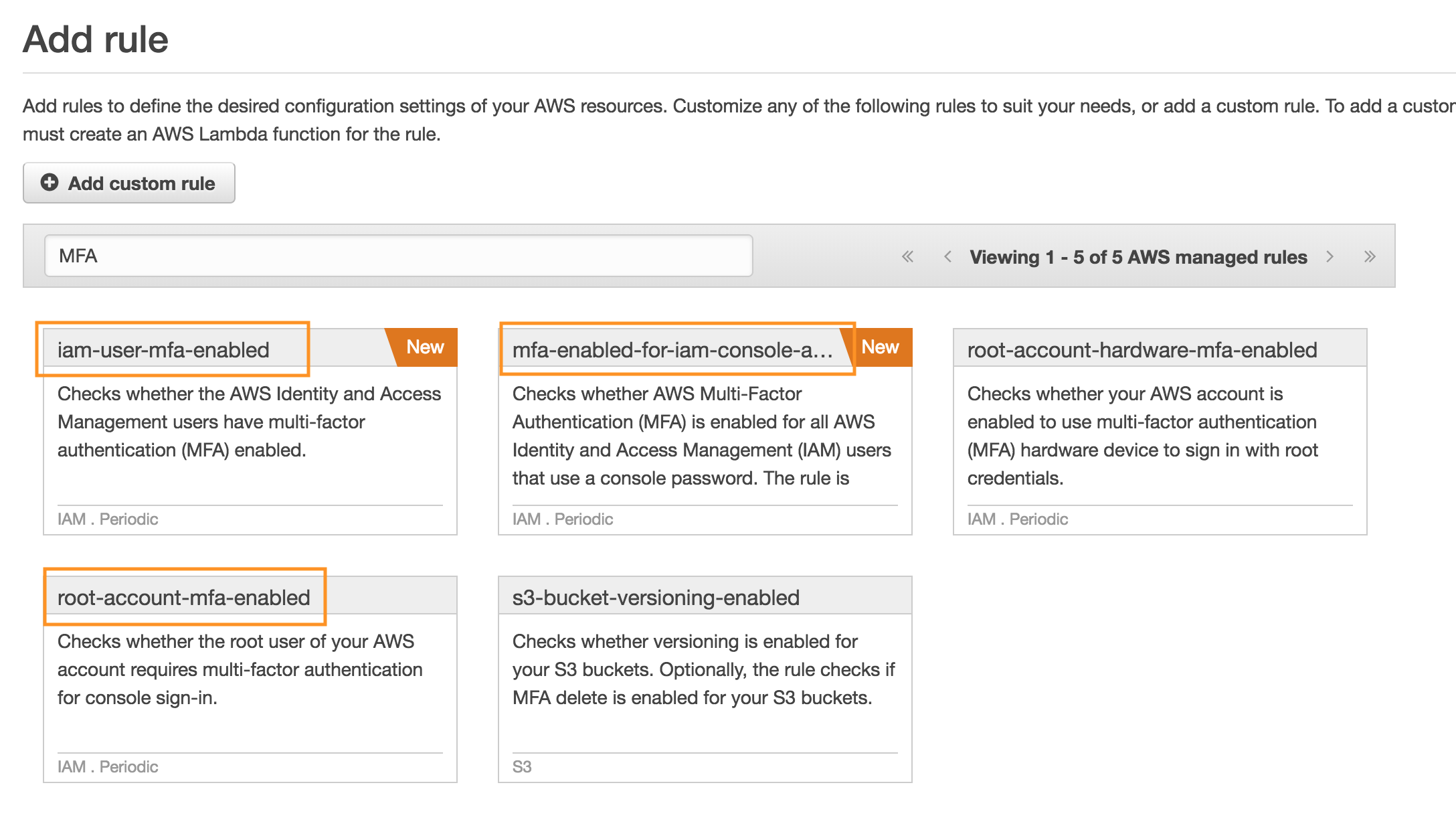
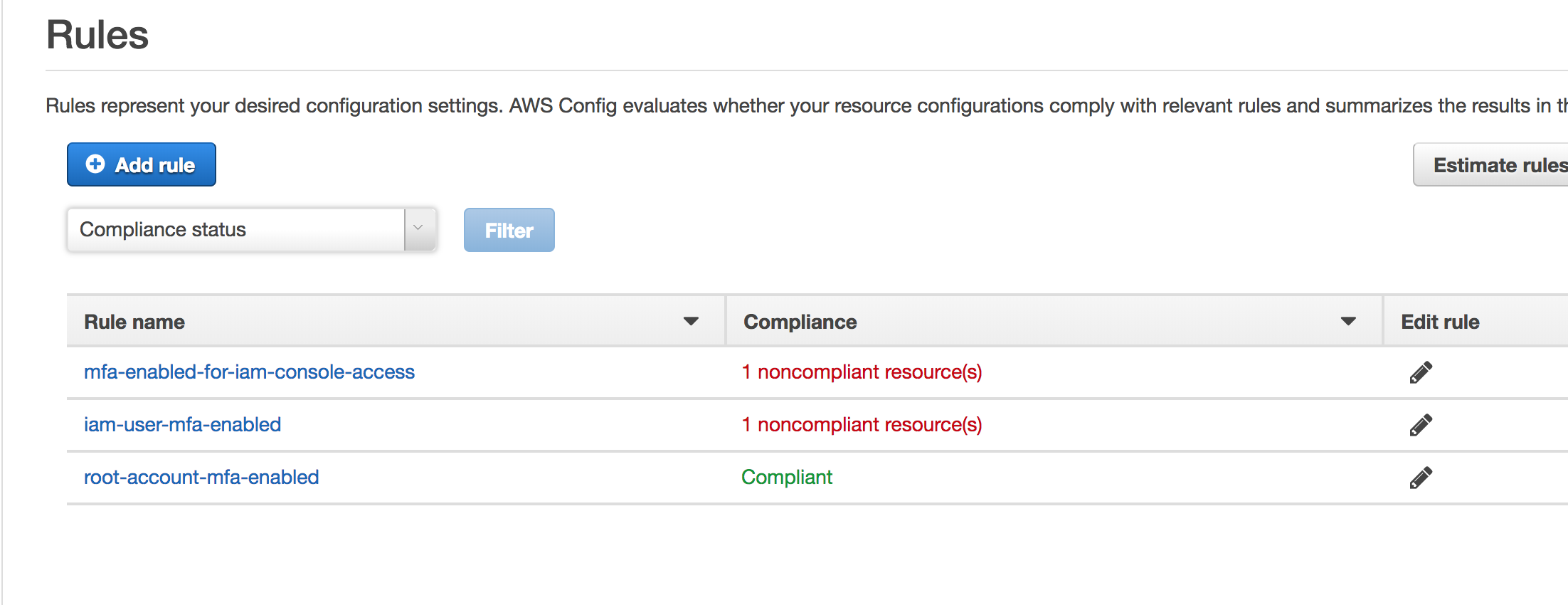
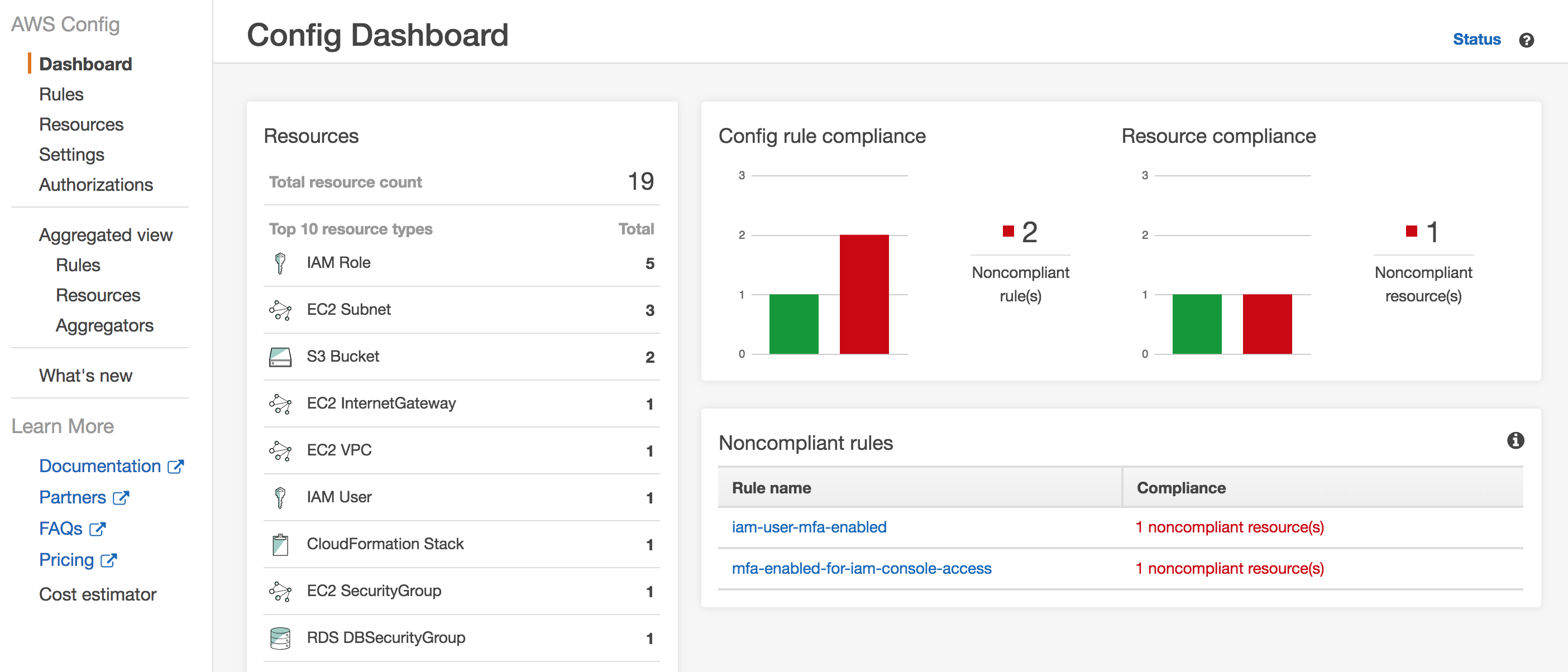
Auditing AWS events with CloudTrail
Another important service under Management & Governance category is CloudTrail.

A nice thing about this service is that it’s already enabled by default with a limited capacity. You can view all AWS API calls made in your account within the last 90 days. This is completely free and enabled out of the box.
To get more out of CloudTrail we need to create trails
Inside Trails
A couple of options about trails:
- It can apply to all regions
- It can apply to all accounts in an organization
- It can record all management events
- It can record data events from S3 and Lambda functions
Just be mindful about the possible extra charges when you log every event for all organization accounts:

Testing the logs
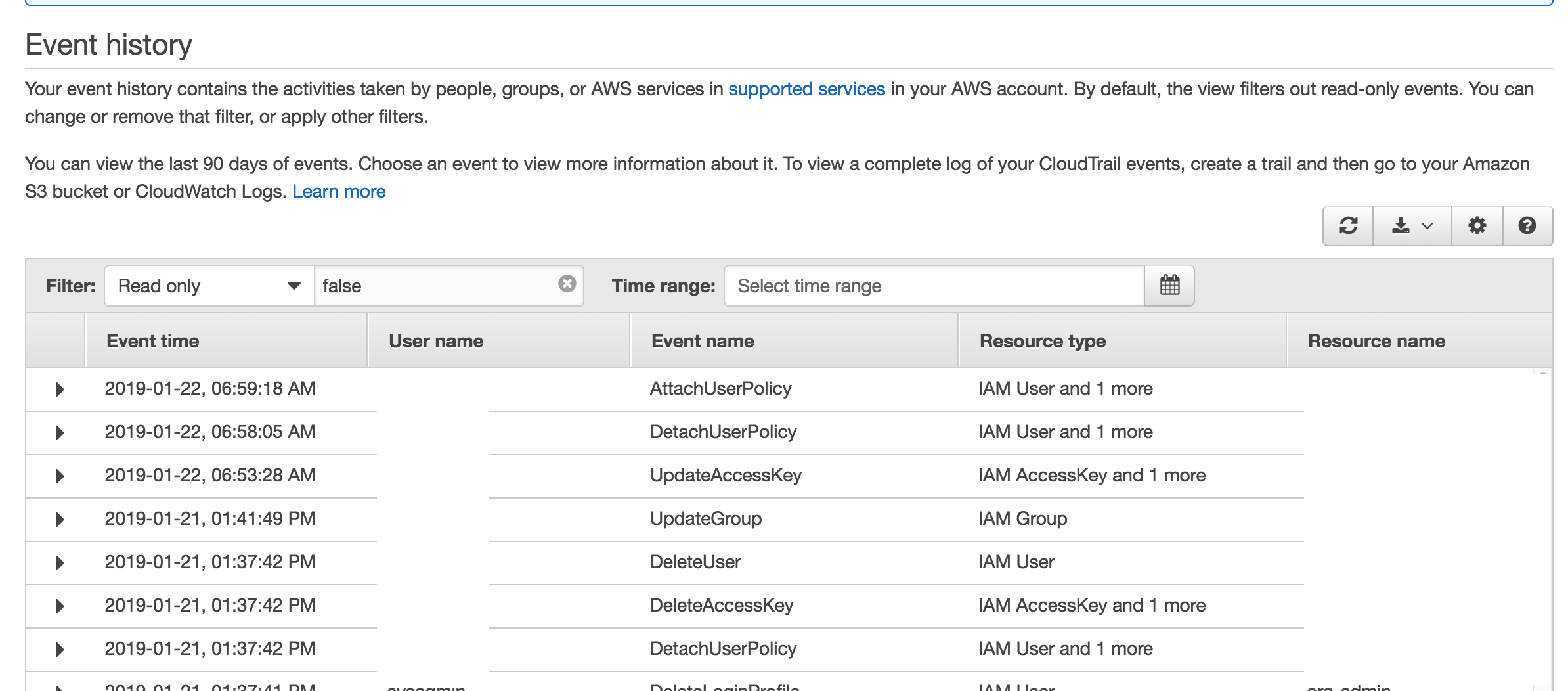
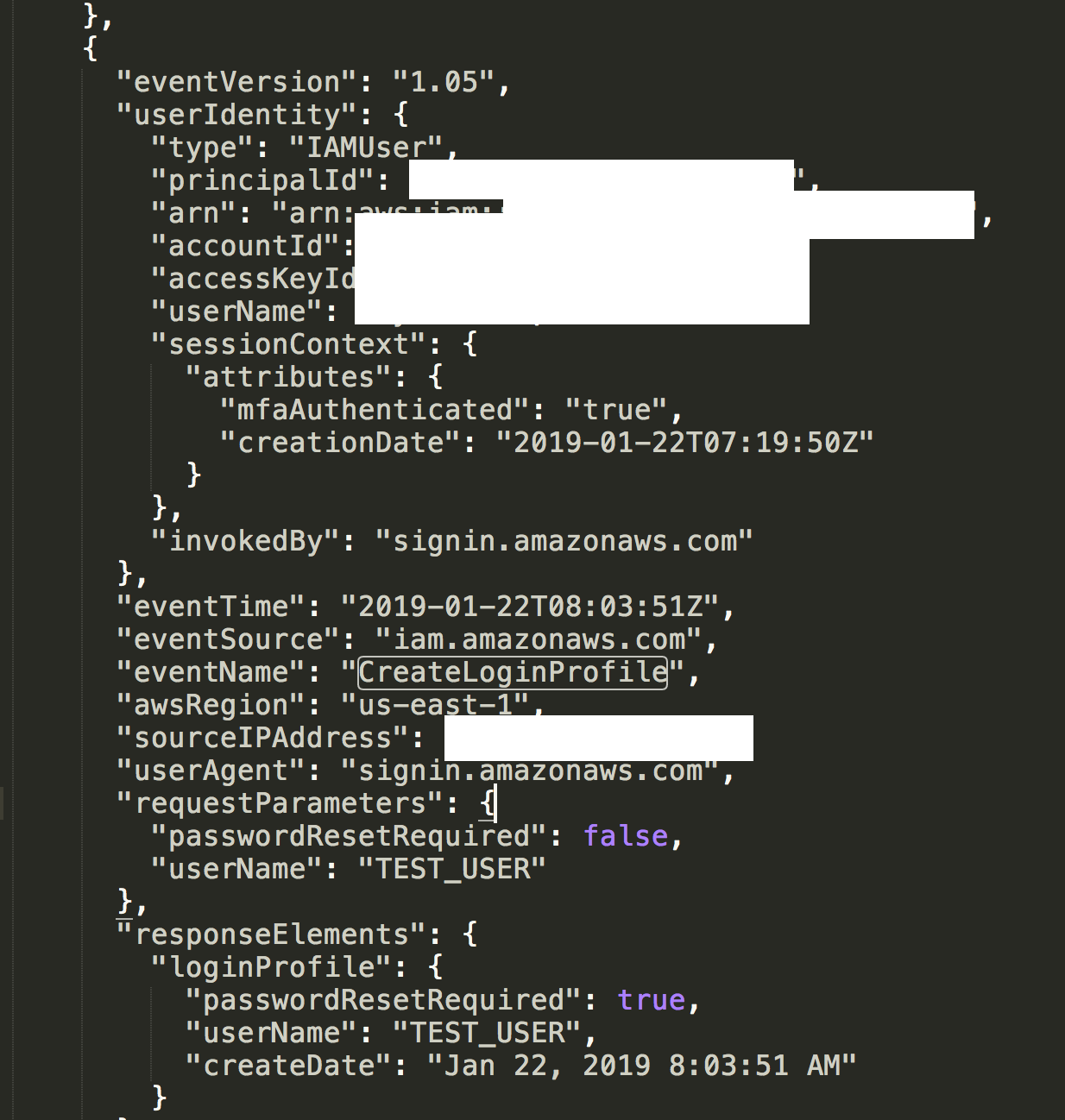
I created a trail that logs all events for all organization accounts. I created an IAM user in another account in the organization. In the event history of the local account events look like this:

These events now can be tracked from master account as well. In the S3 bucket these events are organized by account id and date and they are stored in JSON format:
Conclusion
Having a central storage of all events in across all regions and accounts is a great tool to have. Having the raw data is a good start but making sense of that data is even more important. I’ll keep on exploring CloudTrail and getting more out of it to harden my accounts.