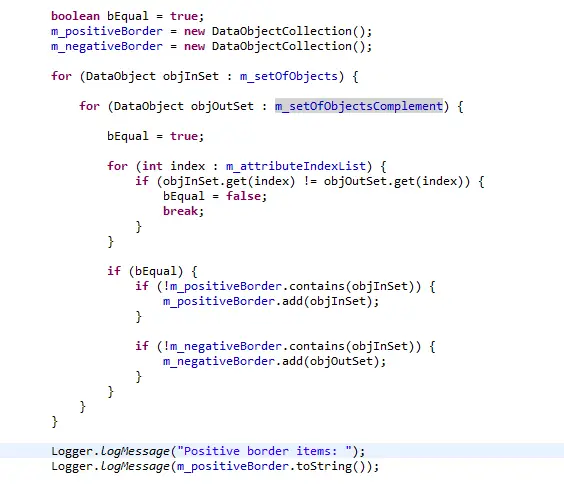
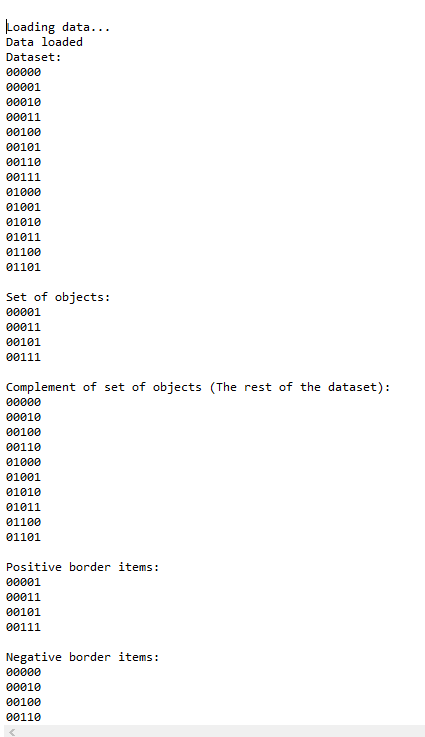
Grid Clustering with CLIQUE Algorithm
CLIQUE (CLustering In QUEst) algorithm is a grid-based clustering algorithm that partitions each dimension of the dataset as a grid.
CLIQUE Implementation
The algorithm starts by assigning each data point to the closest grid in the matrix.
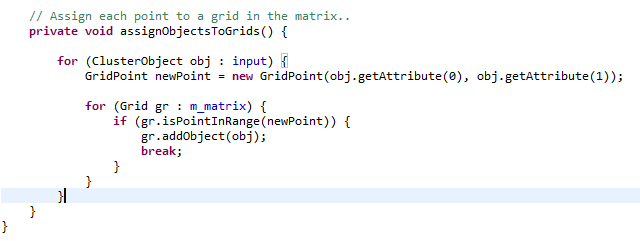
After loading the data it looks something like this:
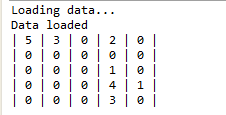
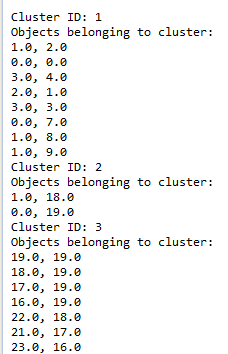
In order for a grid cell to be considered as “dense” it has to have data points more than or equal to the threshold. In this sample the threshold was provided as 2. So after the adjacent dense cells are joined together we get 3 clusters: