Infrastructure as Code with AWS CloudFormation and Cloud Development Kit (CDK)
Introduction
Using AWS is great as it simplifies and improves infrastructure provisioning and maintenance quite a lot. As you depend more and more on AWS you quickly realize that managing everything through AWS Management Console is not an ideal way.
Earlier this year, I published this post about AWS CloudFormation. This post will also discuss using CloudFormation but by taking it a higher level by using AWS Cloud Development Kit (CDK).
Levels of infrastructure
I liked the way the several approaches of infrastructure management is illustrated as levels here: Develop a Web App Using Amazon ECS and AWS Cloud Development Kit (CDK) - AWS Online Tech Talks (YouTube Video)
In a nutshell, those levels are:
Level 0: By hand
This approach is simply using AWS Management Console user interface to manage the infrastructure.
Pros:
- Simple and easy
- Helps to get results faster for exploratory projects
Cons:
- Hard to reproduce
- Possible inconsistencies based on people’s preferences
- Error-prone
- Slow for complex systems
Level 1: Imperative Infrastructure as Code
In this approach you write your own scripts using AWS SDK and manage the resources programmatically.
Pros:
- Repeatable and reusable
- Can be source-controlled
Cons:
- Lots of boilerplate code
- It needs to address all edge cases
Level 2: Declarative Infrastructure as Code
Describe the infrastructure as a script (in JSON or YAML) and use an resource provisioning engine such as AWS CloudFormation or HashiCorp Terraform which in turn use AWS SDK to manage the infrastructure.
Pros:
- No boilerplate
- Creating and updating resources is handled automatically
Cons:
- Templates can become verbose
- Implementing logic is limited to some built-in helper functions
Level 3: AWS Cloud Development Kit
In this approach software is developed using AWS CDK which generates the input for AWS CloudFormation.
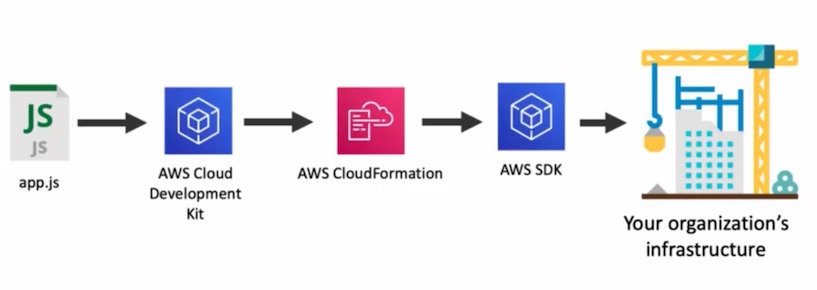
The application can be developed in a number of languages. At the time of this writing the following languages are supported: TypeScript, JavaScript, Python, Java, C#.
Pros:
- Handles creation of underlying resources. For example, when creating a VPC it also automatically generates YAML for all other networking resources (routing tables, NAT gateways etc) that are required by VPC.
- Helps with local workflow
- CDK constructs are reusable. Can be developed by AWS or third parties and can be installed separately.
- Ability to use familiar programming languages
Cons:
- Extra installation
Basic Concepts
- Construct: Basic building block for an AWS CDK app. Represents a “cloud component” and encapsulates everything AWS CloudFormation needs to create the component. They can be developed or downloaded from AWS Construct Library
- Stack: Constructs need to be created within the scope of a Stack. This corresponds to a CloudFormation template.
- App: Stacks are created in the scope of an App. An App can contain multiple stacks.
CDK Basics
- In order to create an application that uses CDK we need to install the CDK
- The application can have one of the 3 supported templates:
- app: General purpose application. This is the default template
- lib: Used to develop a CDK construct
- sample-app: Creates an application already populated with a sample CDK application.
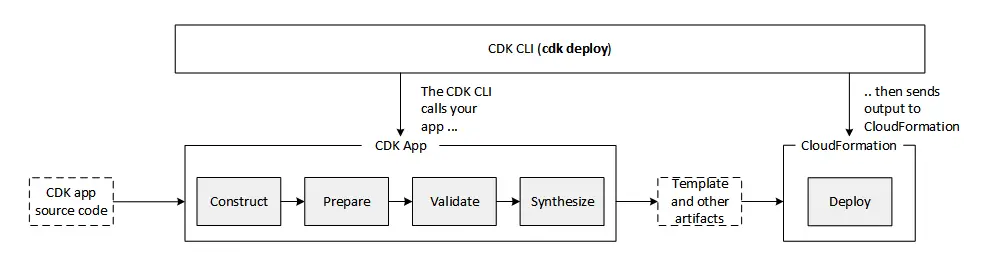
- The following diagram illustrates the app lifecycle:
Installing CDK
AWS CDK is developed using TypeScript. It’s available via npm:
npm install -g aws-cdk
Using CDK
In my example, I will use C#. A new project can be created by using cdk init command:
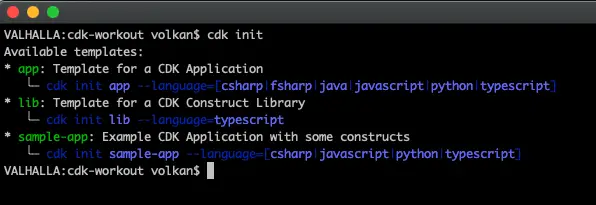
It expects 2 parameters: Language (Can be one of these: csharp, fsharp, java, javascript, python or typescript).
cdk init app --language csharp
To test my first app, I followed the sample app provided and added an S3 construct to my code:
public class CdkWorkoutStack : Stack
{
public CdkWorkoutStack(Construct parent, string id, IStackProps props) : base(parent, id, props)
{
_ = new Bucket(this, "CdkBucket", new BucketProps
{
Versioned = true
});
}
}
Next step is to synnthesize a CloudFormation template by running
cdk synth
This generates a folder called cdk.out which contains a file named CdkWorkoutStack.template.json and with the following contents:
{
"Resources": {
"CdkBucket2FB0D10E": {
"Type": "AWS::S3::Bucket",
"Properties": {
"VersioningConfiguration": {
"Status": "Enabled"
}
},
"UpdateReplacePolicy": "Retain",
"DeletionPolicy": "Retain",
"Metadata": {
"aws:cdk:path": "CdkWorkoutStack/CdkBucket/Resource"
}
}
}
}
Final step is to create the resources by running
cdk deploy
This produces the following results:
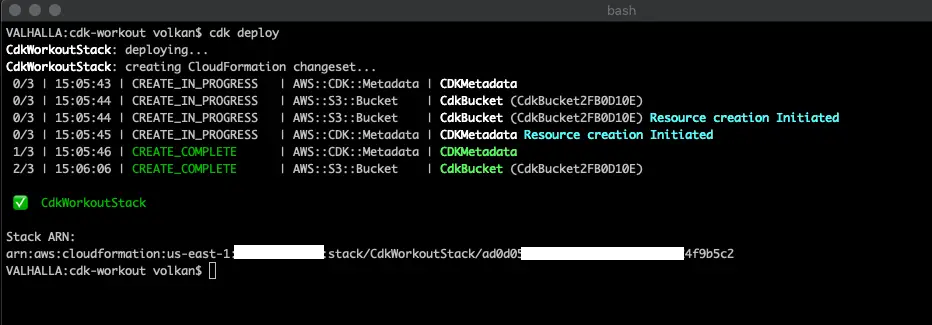
And not surprisingly a CloudFormation stack with the bucket is created in AWS.
In the next version I’m going to change some properties of the bucket such as:
public class CdkWorkoutStack : Stack
{
public CdkWorkoutStack(Construct parent, string id, IStackProps props) : base(parent, id, props)
{
_ = new Bucket(this, "CdkBucket", new BucketProps
{
Versioned = true,
BlockPublicAccess = new BlockPublicAccess(new BlockPublicAccessOptions()
{
BlockPublicAcls = true,
BlockPublicPolicy = true
})
});
}
}
After this change in the code we can review what’s going to be updated by running the following command:
cdk diff
and it produces the following result outlining the changes between the current code and the deployed version:
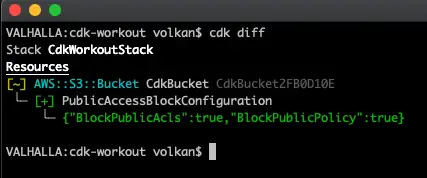
And the stack can be deleted by running the following command:
cdk destroy
In the CDK version I’m using the default deletion policy is to retain. That’s why when I deleted the stack via CDK it didn’t delete the bucket. In order to change that behaviour I had to change the value to delete as such:
public class CdkWorkoutStack : Stack
{
public CdkWorkoutStack(Construct parent, string id, IStackProps props) : base(parent, id, props)
{
var bucket = new Bucket(this, "CdkBucket", new BucketProps
{
Versioned = true,
BlockPublicAccess = new BlockPublicAccess(new BlockPublicAccessOptions()
{
BlockPublicAcls = true,
BlockPublicPolicy = true
})
});
var resource = bucket.Node.FindChild("Resource") as Amazon.CDK.CfnResource;
resource.ApplyRemovalPolicy(RemovalPolicy.DESTROY);
}
}
This time it produces a CloudFormation template with a different policy:
{
"Resources": {
"CdkBucket2FB0D10E": {
"Type": "AWS::S3::Bucket",
"Properties": {
"PublicAccessBlockConfiguration": {
"BlockPublicAcls": true,
"BlockPublicPolicy": true
},
"VersioningConfiguration": {
"Status": "Enabled"
}
},
"UpdateReplacePolicy": "Delete",
"DeletionPolicy": "Delete",
"Metadata": {
"aws:cdk:path": "CdkWorkoutStack/CdkBucket/Resource"
}
}
}
}
This time after destroy command it did delete the bucket as well.
Conclusion
I think infrastructure as code is definitely the way to manage cloud resources and CDK provides a great way to simplify the process. It’s at early stages for the time being as the NuGet packages are in devpreview mode but it’s good enough to rely on and start developing with CDK.