Building Plugin-Based Applications with Managed Extensibility Framework (MEF)
In this post I will try to cover some of the basic concepts and features of MEF over a working example. In the future I’ll post more articles demonstraint MEF usage with more complex applications.
Background
Many successful and popular applications, such as Visual Studio, Eclipse, Sublime Text, support a plug-in model. Adopting a plugin-based model, whenever possible, has quite a few advantages:
- Helps to keep the core lightweight instead of cramming all features into the same code-base.
- Helps to make the application more robust: New functionality can be added without changing any existing code.
- Helps to make development easier as different modules can be developed by different people simultaneously
- Allows plugin development without distributing the main the source code
Extensibility is based on composition and it is very helpful to build SOLID compliant applications as it adopts Open/closed and Dependency Inversion principles.
MEF is part of .NET framework as of version 4.0 and it lives inside System.ComponentModel.Composition namespace. This is also the standard extension model that has been used in Visual Studio. It is not meant to replace Invesion of Control (IoC) frameworks. It is rather meant to simplify building extensible applications using dependency injection based on component composition.
Some terminology
Before diving into the sample, let’s look at some MEF terminology and core terms:
-
Part: Basic elements in MEF are called parts. Parts can provide services to other parts (exporting) and can consume other parts’ services (importing).
-
Container: This is the part that performs the composition. Most common one is CompositionContainer class.
-
Catalog: In order to discover the parts, containers use catalogs. There are various catelogs suplied by MEF such as
- AssemblyCatalog: Discovers attributed parts in a managed code assembly.
- DirectoryCatalog: Discovers attributed parts in the assemblies in a specified directory.
- AggregateCatalog: A catalog that combines the elements of ComposablePartCatalog objects.
- ApplicationCatalog: Discovers attributed parts in the dynamic link library (DLL) and EXE files in an application’s directory and path
-
Export / import: The way the plugins make themselves discoverable is by exporting their implementation of a contract. A contract is simply a common interface that the application and the plugins understand so they can speak the same language so to speak.
Sample Project
As I learn best by playing around, I decided to start with a simple project. I’ve recently published a sample project for Strategy design pattern which I blogged here. In this post I will use the same project and convert it into a plugin-based version.
IP Checker with MEF v1: Bare Essentials
At this point we have everything we need for the first version of the plugin-based IP checker. Firstly, I divided my project into 5 parts:
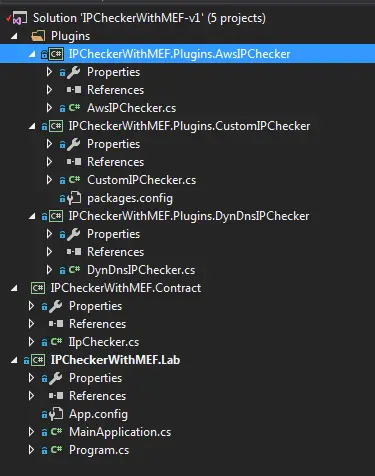
- IPCheckerWithMEF.Lab: The consumer application
- IPCheckerWithMEF.Contract: Project containing the common interface
- Plugins: Extensions for the main application
- IPCheckerWithMEF.Plugins.AwsIPChecker
- IPCheckerWithMEF.Plugins.CustomIPChecker
- IPCheckerWithMEF.Plugins.DynDnsIPChecker
I set the output folder of the plugins to a directory called Plugins at the project level.
Let’s see some code!
For this basic version we need 3 things:
- A container to handle the composition.
- A catalog that the container can use to discover the plugins.
- A way to tell which classes should be discovered and imported
In this sample I used a DirectoryCatalog that points to the output folder of the plugin projects. So after adding the required parts above the main application shaped up to be something like this:
public class MainApplication
{
private CompositionContainer _container;
[ImportMany(typeof(IIpChecker))]
public List<IIpChecker> IpCheckerList { get; set; }
public MainApplication(string pluginFolder)
{
var catalog = new DirectoryCatalog(pluginFolder);
_container = new CompositionContainer(catalog);
LoadPlugins();
}
public void LoadPlugins()
{
try
{
_container.ComposeParts(this);
}
catch (CompositionException compositionException)
{
Console.WriteLine(compositionException.ToString());
}
}
}
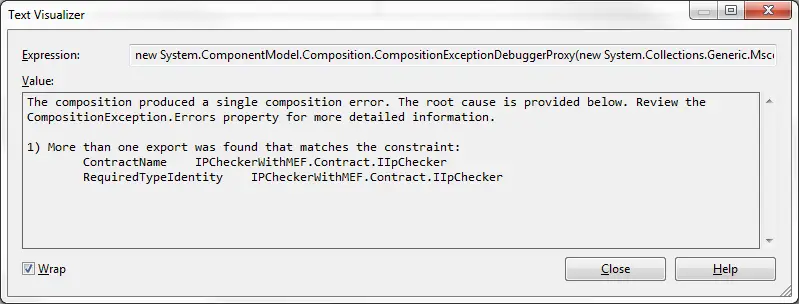
In the constructor, it instantiates a DirectoryCatalog with the given path and passes it to the container. The container imports IIpChecker type objects found in the assemblies inside that folder. Note that we didn’t do anything about IpCheckerList. By decorating it with ImportMany attribute we declared that it’s to be filled by the composition engine. In this example we could only use ImportMany as opposed to Import which would look for a single part to compose. If we used Import we would get the following exception:
Now to complete the circle we need to export our plugins with Export attribute such as:
[Export(typeof(IIpChecker))]
public class AwsIPChecker : IIpChecker
{
public string GetExternalIp()
{
// ...
}
}
Alternatively we can use InheritedExport attribute on the interface to export any class that implements the IIpChecker interface.
[InheritedExport(typeof(IIpChecker))]
public interface IIpChecker
{
string GetExternalIp();
}
This way the plugins would still be discovered even if they weren’t decorated with Export attribute because of this inheritance model.
Putting it together
Now that we’ve seen the plugins that export the implementation and part that discovers and imports them let’s see them all in action:
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Starting the main application");
string pluginFolder = @"..\..\..\Plugins\";
var app = new MainApplication(pluginFolder);
Console.WriteLine($"{app.IpCheckerList.Count} plugin(s) loaded..");
Console.WriteLine("Executing all plugins...");
foreach (var ipChecker in app.IpCheckerList)
{
Console.WriteLine(ObfuscateIP(ipChecker.GetExternalIp()));
}
}
private static string ObfuscateIP(string actualIp)
{
return Regex.Replace(actualIp, "[0-9]", "*");
}
}
We create the consumer application that loads all the plugins in the directory we specify. Then we can loop over and execute all of them:
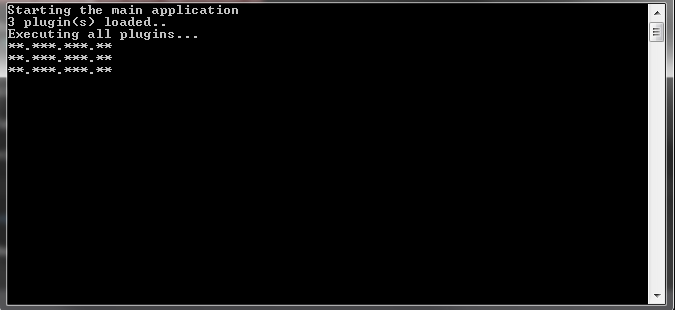
So far so good. Now, let’s try to export some metadata about our plugins so that we can display the loaded plugins to the user.
IP Checker with MEF v2: Metadata comes into play
In almost all applications plugins come with some sort of information so that the user can identify which ones have been installed and what they do. To export the extra data let’s add a new interface:
public interface IPluginInfo
{
string DisplayName { get; }
string Description { get; }
string Version { get; }
}
And on the plugins we fill that data and export it using the ExportMetadata attribute:
[Export(typeof(IIpChecker))]
[ExportMetadata("DisplayName", "Custom IP Checker")]
[ExportMetadata("Description", "Uses homebrew service developed with Node.js and hosted on Heroku")]
[ExportMetadata("Version", "2.1")]
public class CustomIpChecker : IIpChecker
{
// ...
}
In v1, we only imported a list of objects implementing IIpChecker. So how do we accommodate this new piece of information? In order to do that we have to change the way we import the plugins and use the Lazy construct:
[ImportMany]
public List<Lazy<IIpChecker, IPluginInfo>> Plugins { get; set; }
According to MSDN this is mandatory to get metadata out of plugins:
The importing part can use this data to decide which exports to use, or to gather information about an export without having to construct it. For this reason, an import must be lazy to use metadata
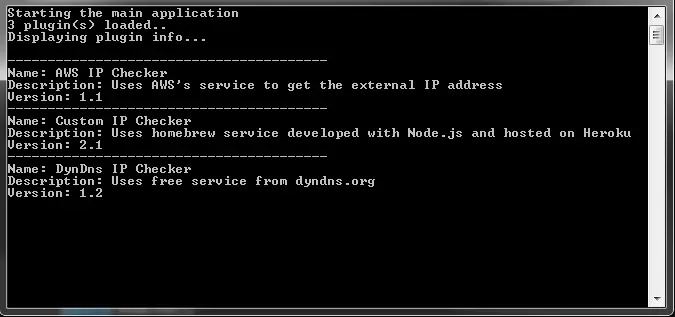
So let’s load and display this new plugin information:
private static void PrintPluginInfo()
{
Console.WriteLine($"{_app.Plugins.Count} plugin(s) loaded..");
Console.WriteLine("Displaying plugin info...");
Console.WriteLine();
foreach (var ipChecker in _app.Plugins)
{
Console.WriteLine("----------------------------------------");
Console.WriteLine($"Name: {ipChecker.Metadata.DisplayName}");
Console.WriteLine($"Description: {ipChecker.Metadata.Description}");
Console.WriteLine($"Version: {ipChecker.Metadata.Version}");
}
}
Notice that we access the metadata through [PluginName].Metadata.[PropertyName] properties. To access the actual plugin and call the exported methods we have to use [PluginName].Value such as:
foreach (var ipChecker in _app.Plugins)
{
ipChecker.Value.GetExternalIp();
}
Managing the plugins
What if we want to add or remove plugins at runtime? We can do it without restarting the application but refreshing the catalog and calling the container’s ComposeParts method again.
In this sample application I added a FileSystemWatcher that listens to the Created and Deleted events on the Plugins folder and calls the LoadPlugins method of the application when an event fires. LoadPlugins first refreshes the catalog and composes the parts:
public void LoadPlugins()
{
try
{
_catalog.Refresh();
_container.ComposeParts(this);
}
catch (CompositionException compositionException)
{
Console.WriteLine(compositionException.ToString());
}
}
But making this change alone isn’t sufficient and we would end up getting a CompositionException:
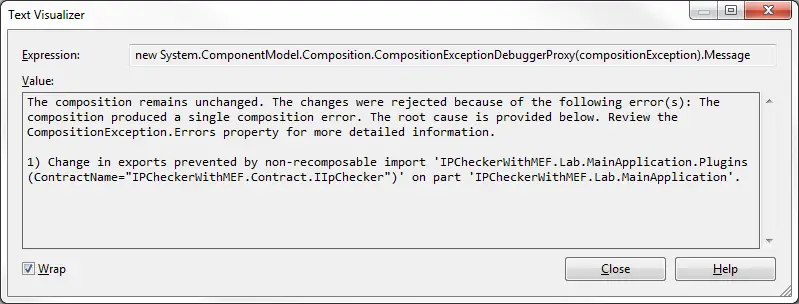
By default recomposition is disabled so we have to specify it explicitly while importing parts:
[ImportMany(AllowRecomposition = true)]
public List<Lazy<IIpChecker, IPluginInfo>> Plugins { get; set; }
After these changes the final version of composing class looks like this:
public class MainApplication
{
private CompositionContainer _container;
private DirectoryCatalog _catalog;
[ImportMany(AllowRecomposition = true)]
public List<Lazy<IIpChecker, IPluginInfo>> Plugins { get; set; }
public MainApplication(string pluginFolder)
{
_catalog = new DirectoryCatalog(pluginFolder);
_container = new CompositionContainer(_catalog);
LoadPlugins();
}
public void LoadPlugins()
{
try
{
_catalog.Refresh();
_container.ComposeParts(this);
}
catch (CompositionException compositionException)
{
Console.WriteLine(compositionException.ToString());
}
}
}
and the client app:
class Program
{
private static readonly string _pluginFolder = @"..\..\..\Plugins\";
private static FileSystemWatcher _pluginWatcher;
private static MainApplication _app;
static void Main(string[] args)
{
Console.WriteLine("Starting the main application");
_pluginWatcher = new FileSystemWatcher(_pluginFolder);
_pluginWatcher.Created += PluginWatcher_FolderUpdated;
_pluginWatcher.Deleted += PluginWatcher_FolderUpdated;
_pluginWatcher.EnableRaisingEvents = true;
_app = new MainApplication(_pluginFolder);
PrintPluginInfo();
Console.ReadLine();
}
private static void PrintPluginInfo()
{
Console.WriteLine($"{_app.Plugins.Count} plugin(s) loaded..");
Console.WriteLine("Displaying plugin info...");
Console.WriteLine();
foreach (var ipChecker in _app.Plugins)
{
Console.WriteLine("----------------------------------------");
Console.WriteLine($"Name: {ipChecker.Metadata.DisplayName}");
Console.WriteLine($"Description: {ipChecker.Metadata.Description}");
Console.WriteLine($"Version: {ipChecker.Metadata.Version}");
}
}
private static void PluginWatcher_FolderUpdated(object sender, FileSystemEventArgs e)
{
Console.WriteLine();
Console.WriteLine("====================================");
Console.WriteLine("Folder changed. Reloading plugins...");
Console.WriteLine();
_app.LoadPlugins();
PrintPluginInfo();
}
}
After these changes I started the application with 2 plugins in the target folder and added a 3rd one while it’s running and got this output:
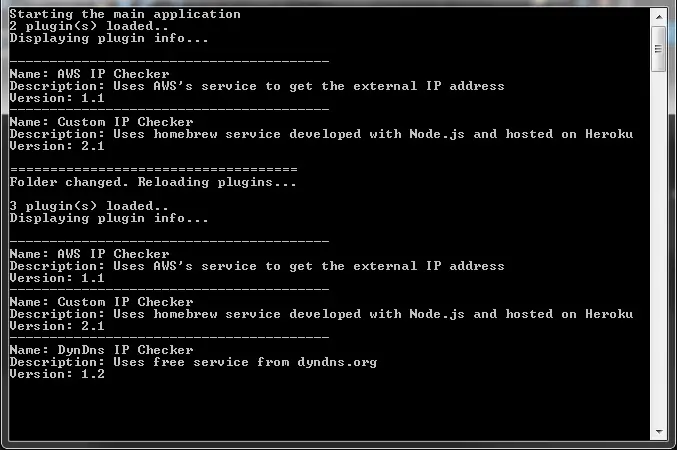
It also works the same way for deleted plugins but not for updates because the assemblies are locked by .NET. Adding new plugins at runtime is painless but removing and updating would require more attention as the plugin might be running at the time.
Resources
- Sample project source code
- IP Checker with strategy design pattern blog post
- MSDN: Managed Extensibility Framework (MEF)
- MSDN: System.ComponentModel.Composition.Hosting Namespace
- MSDN: Attributed Programming Model Overview
- MEF Source Code on Codeplex
- MSDN Magazine Article: Building Composable Apps in .NET 4 with the Managed Extensibility Framework