
Checking domain availability with AWS Route 53 - Part 1
Part 1: Getting supported TLD List
Around this time last year Amazon announced the Route 53 update which allowed domain registrations.
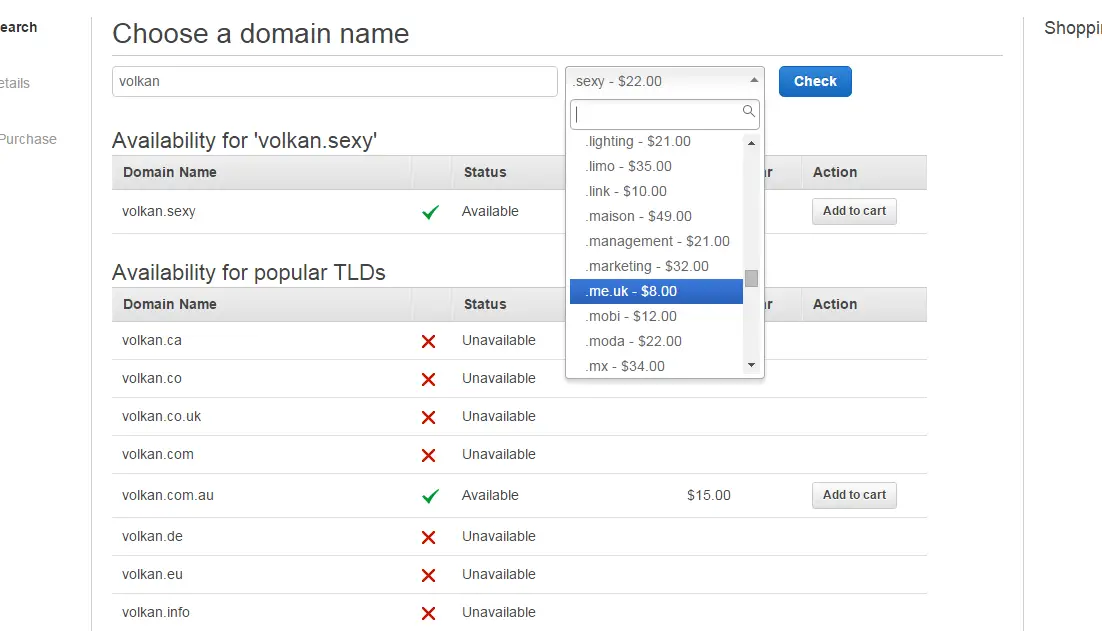
Unfortunately, the AWS Management Console UI doesn’t allow searching all TLDs at once for a given domain. So I set out to write a console application in C# that retrieved the TLDs from AWS API in order to “enhance” AWS a bit. As all of my projects, the scope got out of hand very quickly so I decided to break this adventure into smaller parts. In this post I’ll talk about how to get the supported TLD list.
AWS: Everything is API-based, right? Not quite!
The first step to a domain checker application is to acquire a list of TLDs to check. So I started exploring AWS API to get the supported TLD list. To my surprise there wasn’t any! I asked the question in AWS support forums and the response is it’s not supported. There is a webpage that has the list but that’s it! So until they make it available I decided to do a little scraping to generate the list myself. Obviously this is not the proper way of doing it and it’s prone to breaking very easily but they gave me no choice!
First method: C# Library
It’s just one method and it was easy to implement (apart from fiddling with regular expressions!)
public List<Tld> GetSupportedTldList()
{
Uri supportedTldPage = new Uri("http://docs.aws.amazon.com/Route53/latest/DeveloperGuide/registrar-tld-list.html");
string pageHtml = string.Empty;
using (var webclient = new WebClient())
{
pageHtml = webclient.DownloadString(supportedTldPage);
}
string pattern = "<a class=\"xref\" href=\"registrar-tld-list.html#.+?\">[.](.+?)</a>";
var matches = Regex.Matches(pageHtml, pattern);
var result = new List<Tld>();
foreach (Match m in matches)
{
result.Add(new Tld() { Name = m.Groups[1].Value });
}
return result;
}
It first downloads the raw HTML from the AWS documentation page. The TLDs on the page have a link in this format:
<a class="xref" href="registrar-tld-list.html#cab">.cab</a>
The regular expression pattern retrieves all anchors in this format. Only the ones that contain a dot in the value are retrieved to eliminate irrelevant links. To extract the actual TLD from this matching string I used parenthesis to create a group. By default the whole matched string is the first group. Additional groups can be created by parenthesis so that we can only get the values we are interested in. For example the group values for a match look like this
m.Groups[0].Value: "<a class=\"xref\" href=\"registrar-tld-list.html#academy\">.academy</a>"
m.Groups[1].Value: "academy"
Adds these extracted values to a list (for now Tld class only contains Name property, more info like type of TLD or description can be added in the future)
Second method: JavaScript
It’s not very complicated with C# to accomplish this task so I thought it would be even easier with JavaScript as I already tackled the regular expression bit. I couldn’t be wronger!
I created a simple AJAX call with jQuery and got the following error:

Apparently you cannot get external resources willy nilly using jQuery! It took some time but I found a neat workaround here It’s essentially a jQuery plugin sending the request to query.yahooapis.com instead of the URL we request. Apparently Yahoo API returns the results to a callback method we provide. I hadn’t heard about YQL before. The pitch on their site is:
"The YQL (Yahoo! Query Language) platform enables you to query, filter, and combine data across the web through a single interface."
so a bit explains why they allow Cross-domain queries.
In the test page I added the plugin script
<script-- src="jquery.xdomainajax.js"></script>
Then the main function using jQuery worked just fine:
var supportedTldPage = "http://docs.aws.amazon.com/Route53/latest/DeveloperGuide/registrar-tld-list.html";
function getTldList(callback) {
$.ajax({
url: supportedTldPage,
type: 'GET',
success: function (res) {
var pageHtml = res.responseText;
var jsonResult = parseHtml(pageHtml);
callback(jsonResult);
}
});
}
Another thing I tried was using pure JavaScript:
function getTldList(callback) {
var request = new XMLHttpRequest();
request.open("GET", supportedTldPage, true);
request.onreadystatechange = function () {
if (request.readyState != 4 || request.status != 200) return;
var pageHtml = request.responseText;
var jsonResult = parseHtml(pageHtml);
callback(jsonResult);
};
request.send();
}
This version doesn’t work by default because of the same CORS restrictions. But apparently there’s an extension for that. I installed it and it worked like a charm. Wondering what was happening behind the scenes I captured the request with Fiddler and it looked like this:
Host: docs.aws.amazon.com
Connection: keep-alive
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.89 Safari/537.36
Origin: http://evil.com/
Accept: */*
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,tr;q=0.6
If-None-Match: "19ce8-51b1a64cfe880-gzip"
If-Modified-Since: Fri, 17 Jul 2015 23:17:38 GMT
Origin was “http://evil.com”! Works great as long as it’s not null! In the sample code I’ll leave both versions. Of course all this hassle is to bypass browser restrictions. Depending on your use case, you can always fire the HTTP request above in Fiddler and get the results. I guess it’s a nice mechanism if you need to implement a closed system and want to ensure that resources are not consumed from the outside. Of course for public web pages like this which are meant to be accessed from anywhere in the world there are no restrictions on the server side.
So that now we can get the raw HTML from AWS documentation, the rest is smooth sailing. The part that handles finding the TLDs in the HTML is very similar:
function parseHtml(pageHtml) {
var pattern = /<a class="xref" href="registrar-tld-list.html#.+?">[.](.+?)<\/a>/g;
var regEx = new RegExp(pattern);
var result = {};
result.url = supportedTldPage;
result.date = new Date().toUTCString();
result.tldList = [];
while ((match = regEx.exec(pageHtml)) !== null) {
result.tldList.push(match[1]);
}
var myString = JSON.stringify(result);
return myString;
}
The regular expression pattern is the same. The only difference is .exec method doesn’t return mutliple matches so you have to loop through unless there are no matches.
So finally the result in JSON format is:
{
"url": "http://docs.aws.amazon.com/Route53/latest/DeveloperGuide/registrar-tld-list.html",
"date": "Tue, 29 Jul 2015 20:26:02 GMT",
"tldList": [
"academy",
"agency",
"bargains",
"bike",
"biz",
"blue",
"boutique",
"-- removed for brevity --",
"eu",
"fi",
"fr",
"it",
"me",
"me.uk",
"nl",
"org.uk",
"ruhr",
"se",
"wien"
]
}
What’s next?
Now I have the supported TLD list. I can easily use it in my application but where’s the fun that? I’d rather convert this code into an API so that we can get the new TLDs whenever they are added to that page. I just they don’t change their HTML markup anytime soon! :-)
So in the next post I’ll work on the API…