
Inside the Graph: Cypher
Visual tools are nice and all but they are not as fun as playing with a query language. When you write your own queries the possibilities are endless! In this post I’ll cover the basics of Cypher query language. Cypher is a declarative, SQL-like, pattern-matching query language for Neo4J graph databases.
Basic CRUD Operations
MATCH
Match clause allows to define patterns to search the database. It is similar to SELECT in the RDBMS-world.
MATCH (n) RETURN n
The query above returns all nodes in the database. In this example n is a temporary variable to store the result. The results can be filtered based on labels such as:
MATCH (n:Person) RETURN n
Property-based filters can be used in both MATCH and WHERE clauses. For example the two queries below return the same results:
MATCH (n:Movie {title: "Ninja Assassin"})
RETURN n
MATCH (n:Movie)
WHERE n.title = "Ninja Assassin"
RETURN n
Instead of returning the entire node we can just select some specific properties. If a node doesn’t have the property it simply returns null.
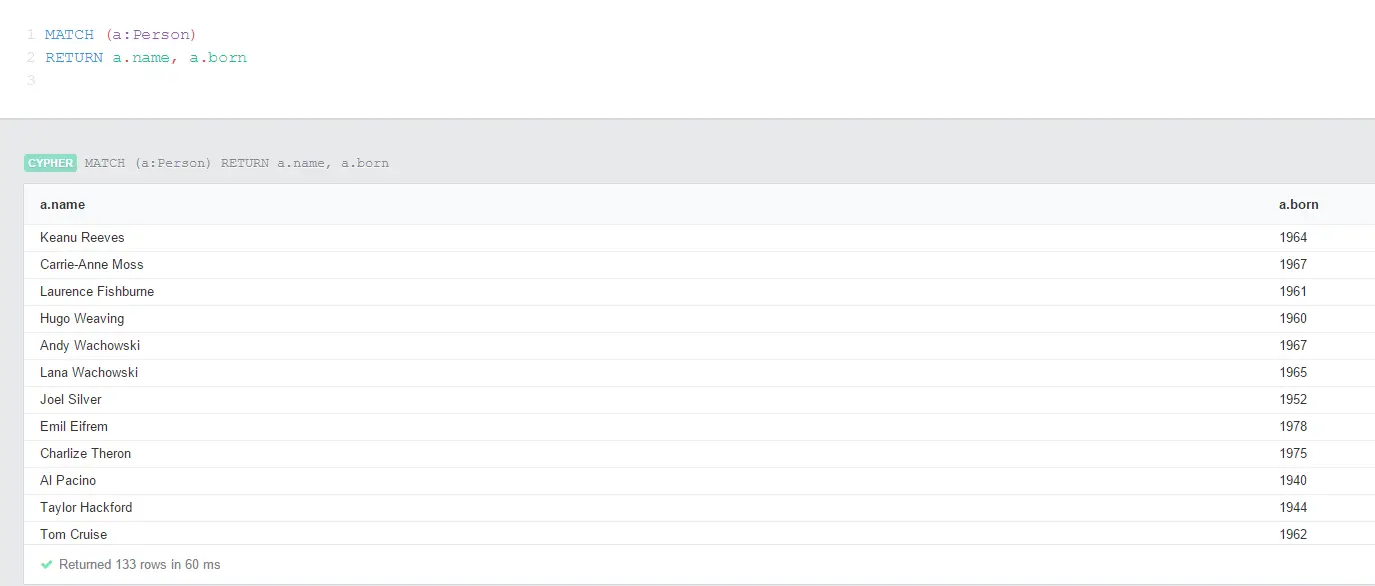
MATCH (a:Person)
RETURN a.name, a.born
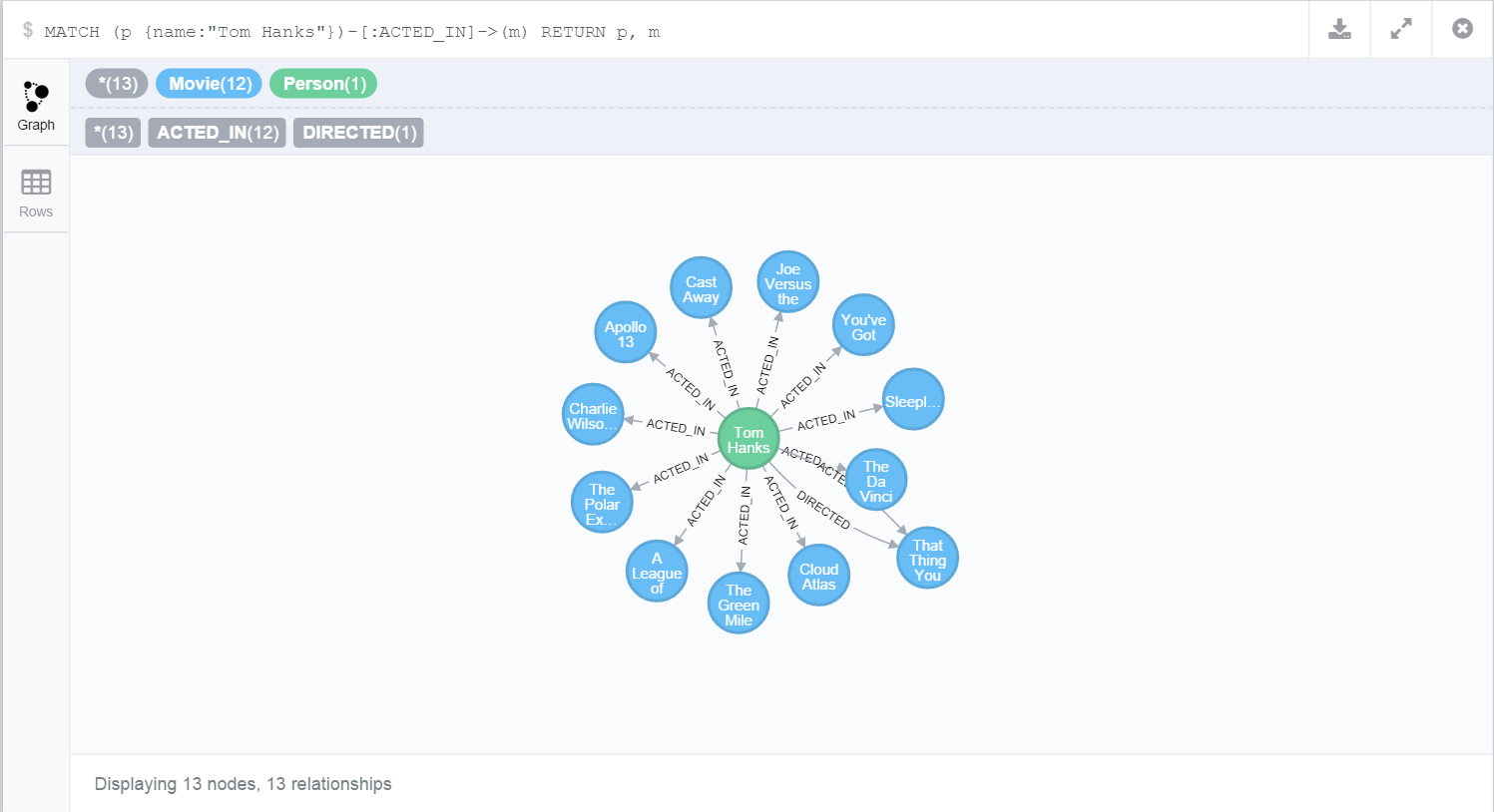
Results can be filtered by relationships as well. For example the query below returns the movies Tom Hanks acted in
MATCH (p {name:"Tom Hanks"})-[:ACTED_IN]->(m)
RETURN p, m
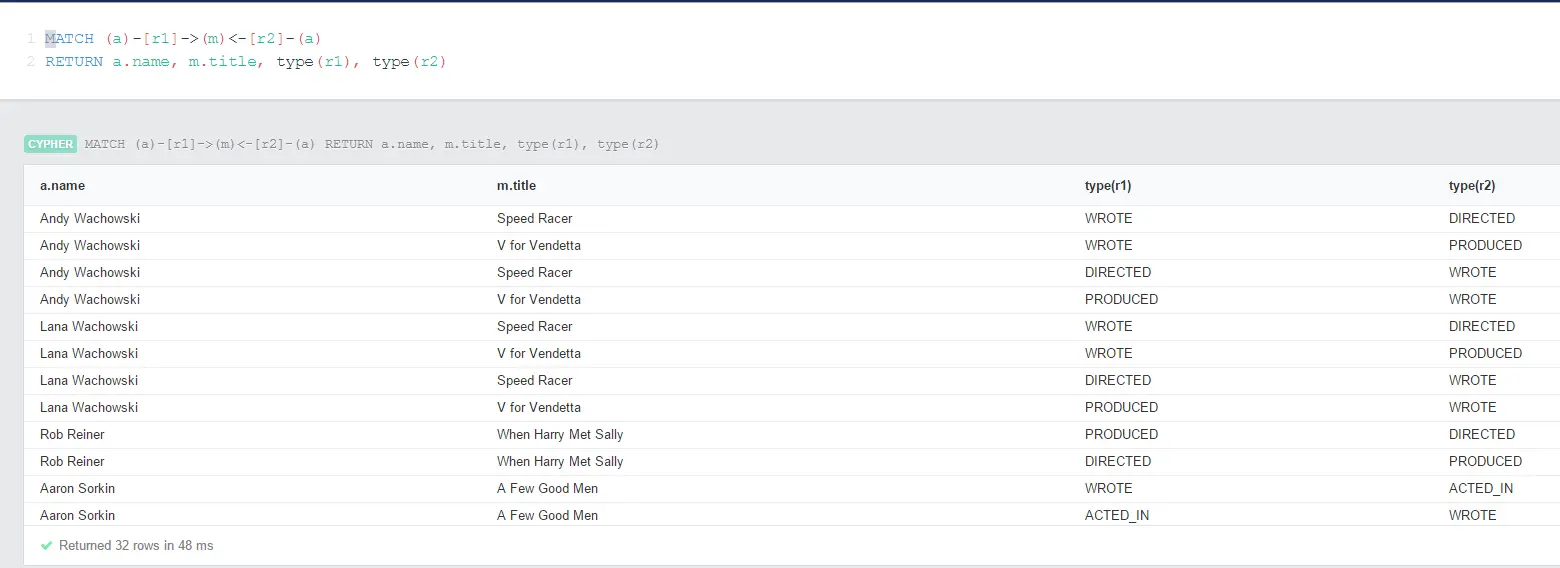
Sometimes we might need to learn the relationship from the query. In that case we can use TYPE function to get the name of the relationship:
MATCH (a)-[r1]->(m)<-[r2]-(a)
RETURN a.name, m.title, type(r1), type(r2)
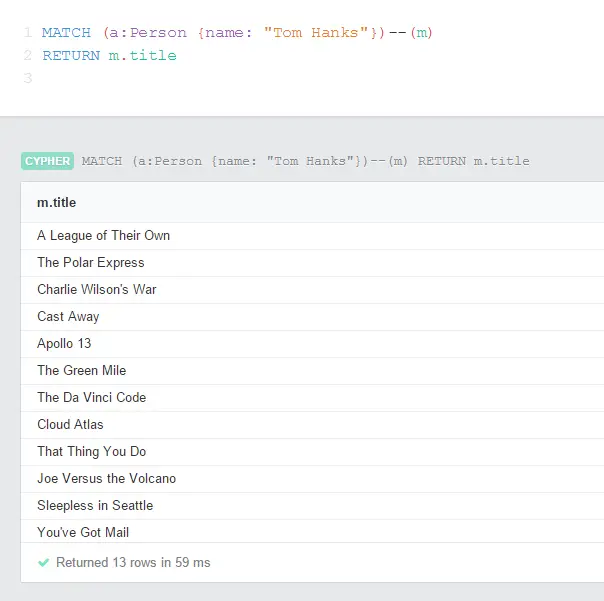
Relationship type and direction can be omitted in the queries. The following query returns the names of the movies that have “some sort of relationship” with Tom Hanks:
OPTIONAL MATCH: OPTIONAL keyword fills in the missing parts in the results with nulls. For example the query below returns 1 row as null because there is no outgoing relationship from the movie The Matrix. If we didn’t use OPTIONAL we would have an empty resultset.
MATCH (a:Movie {title: 'The Matrix'})
OPTIONAL MATCH (a)-[]->(d)
RETURN d
CREATE
To add new data CREATE query is used. In the simplest form the following query creates (a rather useless) node:
CREATE ()
Labels and properties can be set while creating new nodes such as:
CREATE (a:Actor {name: "Leonard Nimoy", born: 1931, died: 2015})
Relationships are created with CREATE as well. For example the following query creates 2 nodes with Person label and creates a MARRIED_TO relationship between them:
CREATE (NedStark:Person {firstname: "Eddard", lastname: "Stark", alias: "Ned", gender: "male"}),
(CatelynStark:Person {firstname: "Catelyn", lastname: "Stark", maidenName: "Tully", gender: "female"})
CREATE (NedStark)-[:MARRIED_TO]->(CatelynStark)
Relationships can have properties too:
CREATE
(WaymarRoyce)-[:MEMBER_OF {order:"Ranger"}]->(NightsWatch)
Properties can be added or updated by using SET keyword such as:
MATCH (p:Person {firstname: "Eddard"})
SET p.title = "Lord of Winterfell"
RETURN p
The above query adds a “title” property to the nodes with label Person and with firstname “Eddard”.
An existing property can be deleted by REMOVE keyword
MATCH (p:Person {firstname: "Eddard"})
REMOVE p.aliasList
MERGE
Merge can be used to create new nodes/relationships or update them if they already exist. In the case of update, all the existing properties must match. For example the following query adds a new property to the node named House Stark of Winterfell
CREATE (houseStark:House {name: "House Stark of Winterfell", words: "Winter is coming"})
MERGE (houseStark {name: "House Stark of Winterfell", words: "Winter is coming"})
SET houseStark.founded = "Age of Heroes"
The following one, on the other hand creates a new node with the same name (because the words properties don’t match):
MERGE (houseStark:House {name: "House Stark of Winterfell", words: "Winter is coming!!!"})
SET houseStark.founded = "Age of Heroes"
RETURN houseStark
I find helpful when you have a long Cyper query and you might run it multiple times. If you just use CREATE every time you run the query you will end up with new nodes. If you use MERGE it will not give any errors and will not create new nodes.
Another way to prevent this is unique constraints. For example the following query will enforce uniqueness on _id property for nodes labelled as Book.
CREATE CONSTRAINT ON (book:Book) ASSERT book._id IS UNIQUE
Now we can run this query and create the books:
CREATE
(AGameOfThrones:Book {_id: "7abe0a1c-b9bd-4f00-b094-a82dfb32b053", title: "A Game of Thrones", orderInSeries: 1, released:"August 1996"}),
(AClashOfKings:Book {_id: "051dae64-dfdb-4134-bc43-f6d2b4b57d37", title: "A Clash of Kings", orderInSeries: 2, released:"November 1998"}),
(AStormOfSwords:Book {_id: "e9baa042-2fc8-49a6-adcc-6dd455f0ba12", title: "A Storm of Swords", orderInSeries: 3, released:"August 2000"}),
(AFeastOfCrows:Book {_id: "edffaa47-0110-455a-9390-ad8becf5c549", title: "A Feast for Crows", orderInSeries: 4, released:"October 2005"}),
(ADanceWithDragons:Book {_id: "5a21b80e-f4c4-4c15-bfa9-1a3d7a7992e3", title: "A Dance with Dragons", orderInSeries: 5, released:"July 2011"}),
(TheWindsOfWinter:Book {_id: "77144f63-46fa-49ef-8acf-350cdc20bf07", title: "The Winds of Winter", orderInSeries: 6 })
If we try to run it again we get the following error:

Unique constraint enforces the existing data to be unique as well. So if we run the book creation query twice, before the constraint, then try to create the constraint we get an error:
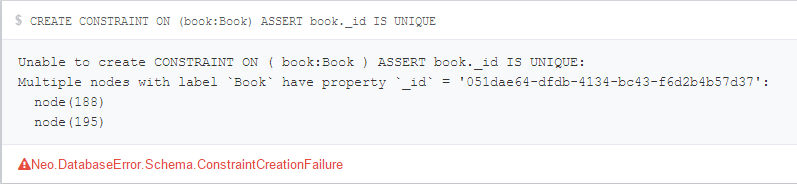
To delete the constraint we use DROP keyword such as
DROP CONSTRAINT ON (book:Book) ASSERT book._id IS UNIQUE
DELETE
To delete nodes first we find them by MATCH. Instead of RETURN in the above examples we use DELETE to remove them.
MATCH (b:Book {_id: "7abe0a1c-b9bd-4f00-b094-a82dfb32b053"})
DELETE b
The above query would only work if the node doesn’t have any relationships. To delete a node as well as its relationships we can use the following:
MATCH (b {_id: "7abe0a1c-b9bd-4f00-b094-a82dfb32b053"})-[r]-()
DELETE b, r
We can generalize the above query to clean the entire database:
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n, r
I find this quite useful during test and development phase as I need to start over quite often.
Useful keywords
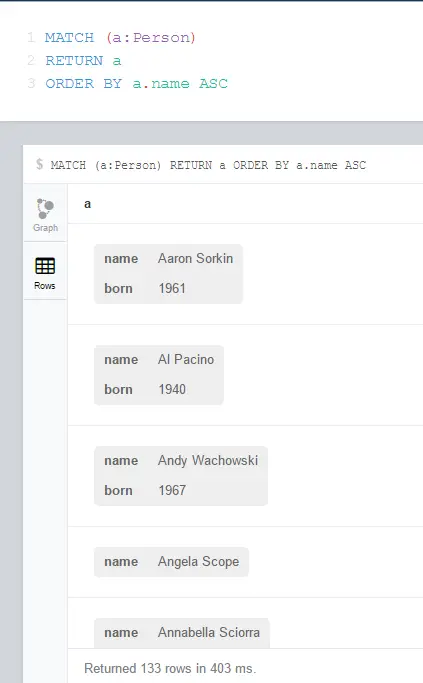
- ORDER BY
It is almost mandatory in all SQL-variants. Eventually you have to sort the data. For example the following returns all actors order by their names in alphabetical order:
- LIMIT
Sometimes your query may return a lot of values that you’re not interested in. For example you may want to get top n results. In this case you can restrict the number of rows returned by LIMIT keyword such as:
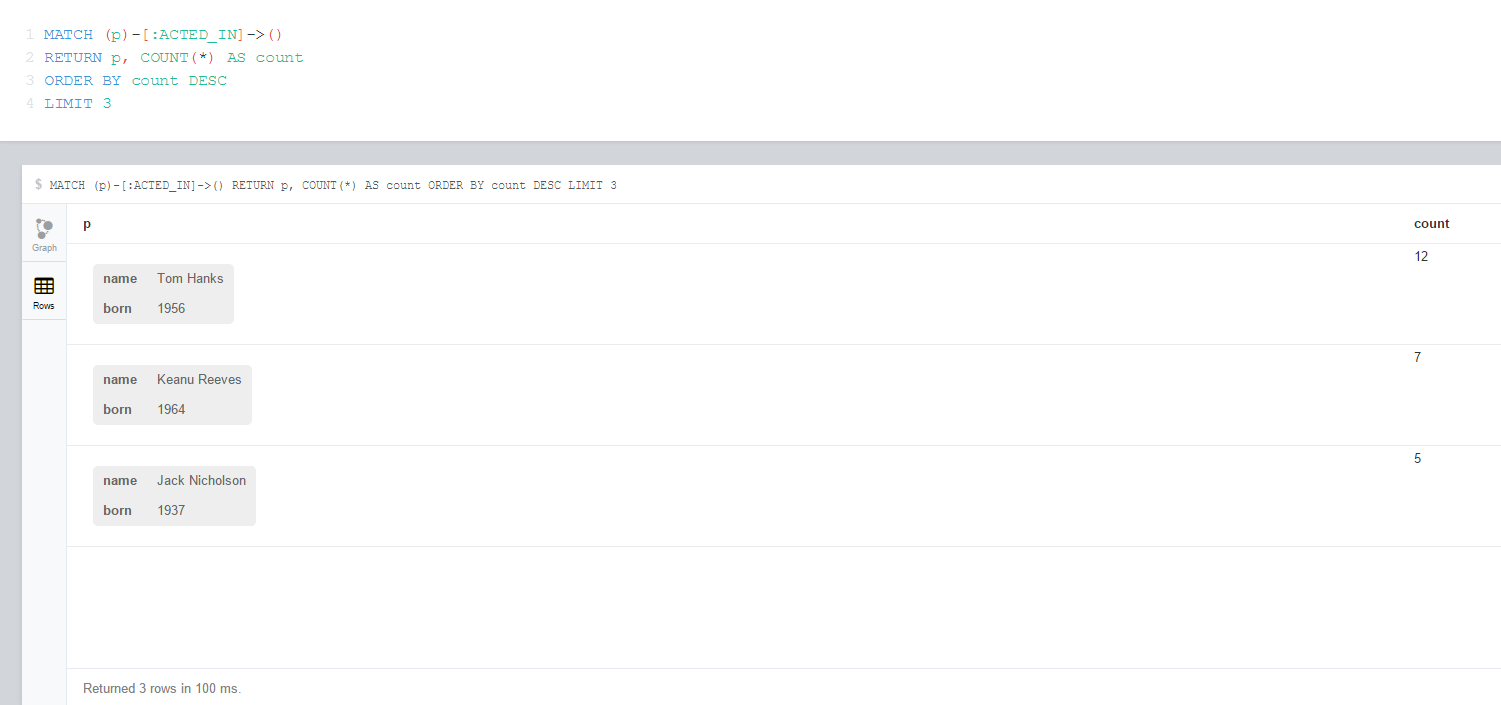
The above query returns the top 3 actors who have the most ACTED_IN relationships with movies in descending order.
- UNION
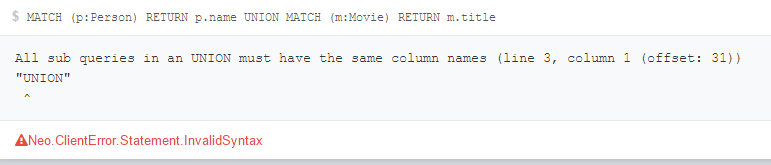
Another similar keyword from RDBMS is UNION. Similar to standard SQL, the returned columns must have the same number and names. For example the following will fail:
MATCH (p:Person)
RETURN p.name
UNION
MATCH (m:Movie)
RETURN m.title
But with using an alias it can be fixed like this:
MATCH (p:Person)
RETURN p.name AS name
UNION
MATCH (m:Movie)
RETURN m.title AS name
Measuring Query Performance
PROFILE keyword is very helpful as it lets you see the query plan and optimize it. It is very simple to use: You just put it before the MATCH clause such as

This is obviously a very simplistic example but I strongly recommend the GrapAware article on Labels vs Indexed Properties. PROFILE is heavily used to identify which option performs better in a given scenario. Also a great read to learn more about modelling Neo4J database.
Conclusion
Cypher is quite powerful and it can be very expressive in the right hands. It is quite comprehensive to cover in a blog post. I just wanted this post to contain various samples for the basic queries. I hope it can be of some help for someone new to Cypher in conjunction with the references I listed below.