
Genetic Algorithm Implementation
Genetic algorithm sounds fascinating to me as in a way it mimics evolution. It’s quite easy to implement and understand.
Genetic Algorithm
The algorithm has 3 stages:
- Selection: Every generation is subjected to a selection process which eliminates the unfit ones.
- Cross-over: This happens randomly among the selected generation and some genomes swap genes.
- Mutation: Some genes are mutated randomly based on a given threshold value for mutation.
Implementation
The implementation starts with generating random bit sequences to represent genomes. The length of the genome and the number of genomes in a generation are specified in the configuration.
First generation is calculated randomly and their fitness is calculated based on the fitness function the system uses. After the groundwork has been done we have a genome pool each with their own fitness values and selection ranges. The width of the selection range is determined by the fitness of the genome. So that the larger the range the more likely they are selected for the next generation.
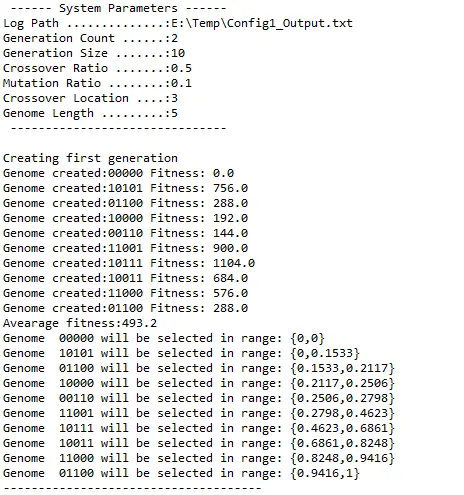
In selection process, a random value is generated and the genome whose selection range includes that value is selected. Same genome can be selected more than once.
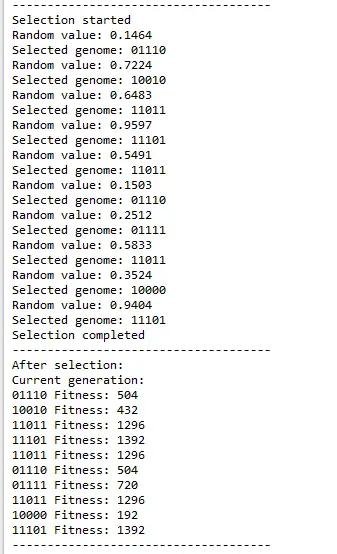
After the next generation is selected and their new fitness values are calculated cross-over starts. In cross-over 2 random genomes are picked and they swap genes. The point in the genome string is specified in the configuration (3 in this example)
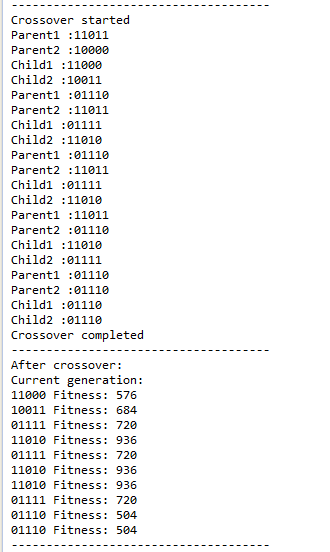
The final phase of the algorithm is mutation. In this step a number of genomes are picked and some bits is flipped randomly.
The most important thing about this algorithm is having a good fitness function that can accurately compute the fitness values for a given feature.
