
k-means Implementation
I’m keeping on reviving my old projects. This is the second data mining algorithm implementation. It is another clustering algorithm called k-means.
k-means Algorithm
Algorithm groups and creates k clusters from n data points. First the cluster centres are picked randomly from the data points. Then the entire dataset is iterated and all points are assigned to their closest cluster. Closest cluster is determined by measuring the distance of the data point to the centroid of the clusters. This process is repeated until there is no change in the dataset and all points are assigned to the closest ones.
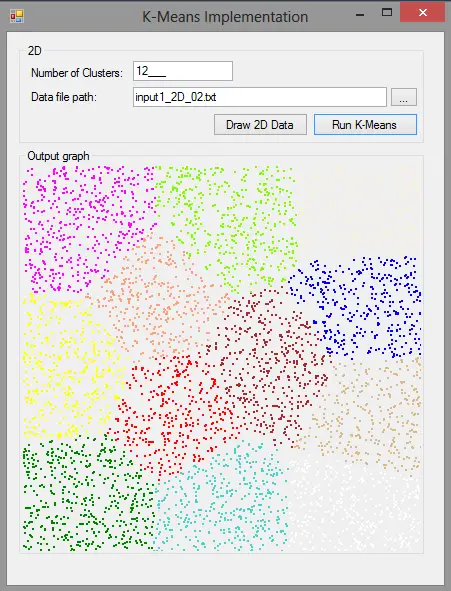
Implementation
The project contains 6 libraries:
- VP.KMeans.Core: Core library including the algorithm implementation
- VP.KMeansClient.GUI: User interface for entering the parameters and plotting the clusters
- VP.KMeansClient.Console: Console user interface. No fancy plots, just an output file is generated
- VP.KMeans.DataGenerator.Core: Library to generate test data
- VP.KMeans.DataGenerator.Console: Console application to feed the core library to generate test data
- CPI.Plot3D: External library to plot the results
