
Introduction to Couchbase – Part 3
In this post we are diving into coding and developing a small application using the beer sample database that ships with Couchbase 2.0.
Environment Setup
To develop a .NET application with a Couchbase backend, we need the Couchbase .NET SDK. The current version as of this writing can be downloaded from here. But the best way to get it using Nuget. Using the SDK is fairly simple. It comes with a main class called *CouchbaseClient. *All operations are performed using this class.
Connecting to server
The first step is connecting to the server and the easiest way to do is using the configuration file.
<configuration>
<configsections>
<section name="couchbase" type="Couchbase.Configuration.CouchbaseClientSection, Couchbase" />
</configsections>
<couchbase>
<servers bucket="beer-sample" bucketpassword="">
<add uri="http://192.168.1.111:8091/pools/" />
<add uri="http://192.168.1.112:8091/pools/" />
</servers>
</couchbase>
</configuration>
As you can see from the configuration section, if you have multiple nodes in the cluster just add their URIs to the servers list. Once IPs and the bucket and the password are specified we are done. We don’t need to explicitly connect to the database, we can just create a new client instance and start calling methods
using (CouchbaseClient client = new CouchbaseClient())
{
// DB operations go here
}
Basic Operations
OK so far so good. We are connected to the server without a hassle. As there is already data in the server let’s get some sample data from the database. As the database is a key/value store we can add any type of data we want to. We can create our JSON objects in a string and insert/update data with it. But most likely we want to use our domain objects instead of manipulating raw JSON. There are 2 things to consider here. Once we tackle those issues the rest is quite easy:
- Mark your objects as Serializable: This is required to persist any object. Once you make the class serializable you can run CRUD operations on it.
- The default serializer is binary serializer. That means when you store an object using by calling Store method you will get something like this when you try to view the object:
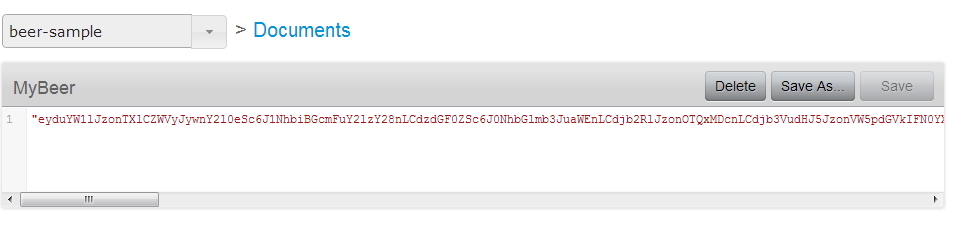
This is not too helpful. We cannot read and index. So we’d rather store it in JSON format. Luckily StoreJson method comes to rescue. The following code produces the result below which is exactly what we wanted. To map the key’s in JSON object to the properties in our class we use JsonProperty attribute in the Newtonsoft.Json library which is used the SDK itself.

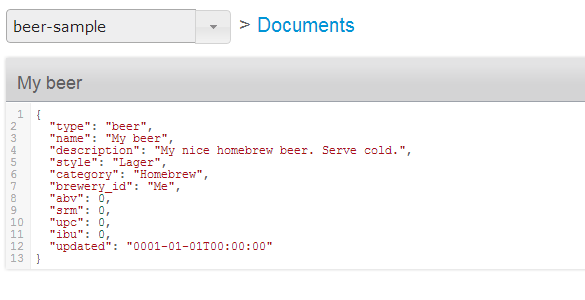
Store and StoreJson methods accept an argument of type StoreMode. The values of StoreMode are Add, Set and Replace. Add is used to create a new record (INSERT), Replace is used to update an existing record (UPDATE). Set adds the record if it doesn’t exist and updates it if it exists (MERGE – but simpler). To delete an object we call the Remove method with the objects key as argument. So basically we perform CRUD operations with Get/GetJson, Store/StoreJson and Remove methods.
Querying database with views
Views in Couchbase 2.0 are functions written in JavaScript that use a technique called Map/Reduce. Map/Reduce is a complex topic that I have not fully covered yet but basically it’s a method for processing large data sets in a distributed environment. It is developed by Google. It involves 2 functions called map and reduce. The map function filters entries for certain information and can extract information. The result of a map function is an ordered list of key/value pairs called an index. The results of map functions are stored in disk by the Couchbase server. Reduce function is optional and can be used to perform sum, aggregate or similar calculations on the output of map function. Views can be grouped in design documents which can be associated with a bucket. I consider them as namespaces. Couchbase Server offers two kinds of views: Development and Production. As creating a view means creating an index. it may incur some overhead on the performance of the system. So development views are handy to fully test before publishing to production environment. Also production views cannot be edited via admin console which forces the developer to develop and test the view in development environment first. So to demonstrate what they look like let’s examine the view that returns all the breweries.
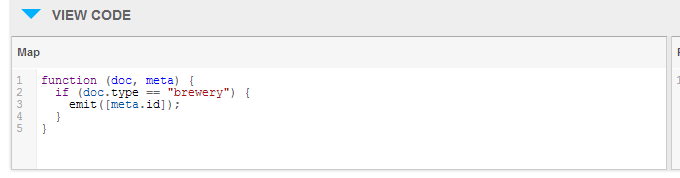
We have 2 types of objects in the database (beer and brewery). This function only emits the objects that are of type brewery.
Demo
So all this theory means nothing if we don’t put it into good use. You can get source code of the sample application (I call it Beer Explorer) from my Github account. Also if you want to see what it looks like before diving into the code I host a live version here: http://beerexplorer.me. Feel free to play with it.