
Disassembling And Decompiling .NET Assemblies
Generally we don’t need to understand how every single line of code is compiled but sometimes it helps to have a look at what’s going on under the hood. The code we write doesn’t always translate directly to IL (Intermediate Language) by the compiler (assuming optimizations come into play). It also helps what really happens when we use shorthand notations in the language. So I decided to explore the IL and see how simple constructs are compiled. Some of them are very simple and commonly known but some of them were new to me so compiled all of them in this post.
Toolkit
I used a disassembler and decompilers to analyze the output. When we compile a .NET program, it’s converted into IL code. Using a disassembler we can view the IL. Decompiling is the process of regenerating C# code. It’s hard to read IL so getting the C# code back helps to analyse easier. I used the following tools to view the IL and C# code:
- ILDASM: Main tool I used is ILDASM (IL Disassembler). It’s installed with Visual Studio so doesn’t require anything special. It’s hard to make sense of IL but generally helpful to get an idea about what’s going on.
- Telerik JustDecompile: Decompiler takes an assembly and re-generates .NET code from it. It may not fully return the original source code and sometimes it optimizes stuff so it may skew the results a little bit. But it’s generally helpful when you need to see a cleaner representation
- ILSpy: Same functionality as JustDecompile. I used it to compare the decompiled results.
So without further ado, here’s how some language basics we use are compiled:
01. Constructor
When you create a new class the template in Visual Studio creates a simple blank class like this:
namespace DecompileWorkout
{
class TestClass
{
}
}
and we can create instances of this class as usual:
var newInstance = new TestClass();
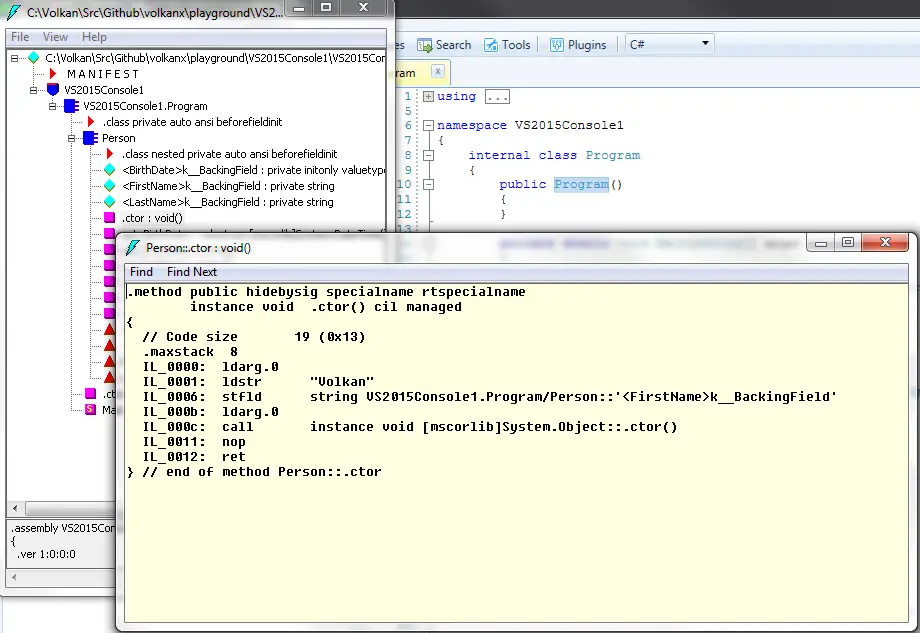
It works even though we don’t have a constructor in our source code. The reason it works is that the compiler adds the default constructor for us. When we decompile the executable we can see it’s in there:
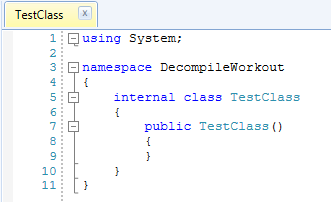
But when we add a constructor that accepts parameters the default constructor is removed:
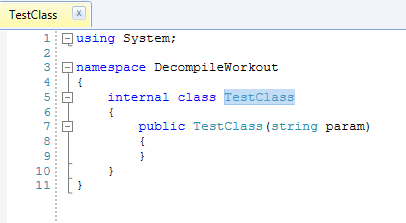
It makes sense otherwise all classes would have parameterless constructor no matter what you do.
02. Properties
Properties have been supported since forever and they are extremely handy. In the olden days we used to create a field and create getter and setter methods that access that field such as:
private string _name;
public void SetName(string name)
{
_name = name;
}
public string GetName()
{
return _name;
}
Now we can get the same results by
public string Name { get; set; }
What happens under the hood is the compiler generates the backing field and getter/setter methods. For example if we disassemble the class with the above we’d get something like this:
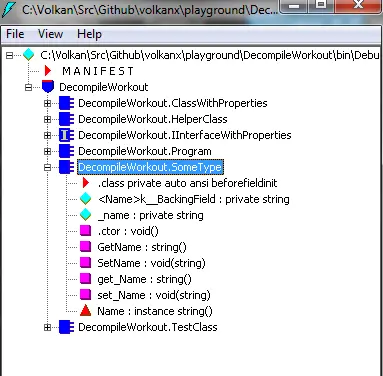
Apart from the weird naming (I guess it’s to avoid naming collisions) it’s exactly the same code.
The backing field is only generated when this shorthand form is used. If we implement the getter/setter like this
public string Name
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
Then the generated IL only contains the methods and not the backing field
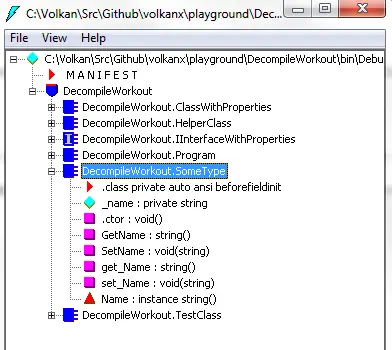
One last thing to note is that we cannot have fields on interfaces but we are allowed to have properties. It’s because when used on interfaces the compiler again generates only the getter and setter methods.
03. Using statement
A handy shortcut to use when dealing with IDisposable objects is the using statement. To see what happens when we use using I came up with this simple code:
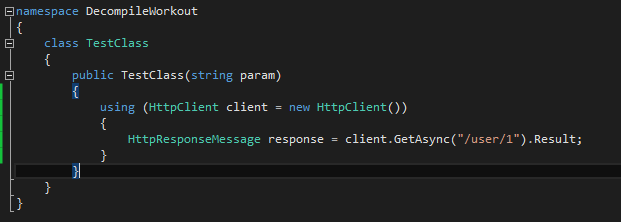
After decompiling:

So basically it just surrounds the code with a try-finally block and calls Dispose method of the object if it’s not null. Instead of writing this block of code it’s very handy to use the using statement. But at the end there is nothing magic about it, it’s just a shortcut to dispose objects securely.
04. var keyword and anonymous types
var keyword is used to implicitly specify a type. The compiler infers the type from the context and generates the code accordingly. Variables defined with var keyword are still strongly typed because of this feature. Initially I resisted using it as a shortcut because it’s main purpose is not to provide the luxury not to create implicitly typed variables. It’s introduced at the same time as anonymous types which makes sense because without having such a keyword you cannot store anonymous objects. But I find myself using it more and more for implicitly specifying the types. Looking around I see that I’m not the only one so if it’s just laziness at least I’m not the only one to blame!
So let’s check out how this simple code with one var and an anonymous type:
public class UsingVarAndAnonymousTypes
{
public UsingVarAndAnonymousTypes()
{
var someType = new SomeType();
var someAnonymousType = new { id = 1, name = "whatevs" };
}
}
Decompiling the code doesn’t show the anonymous type side of the story but we can see that var keyword is simply replaced with the class type.
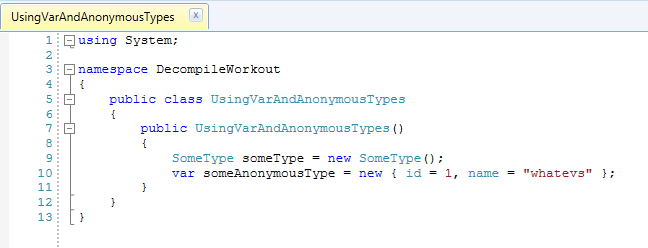
To see what happens with anonymous types let’s have a look at the IL:
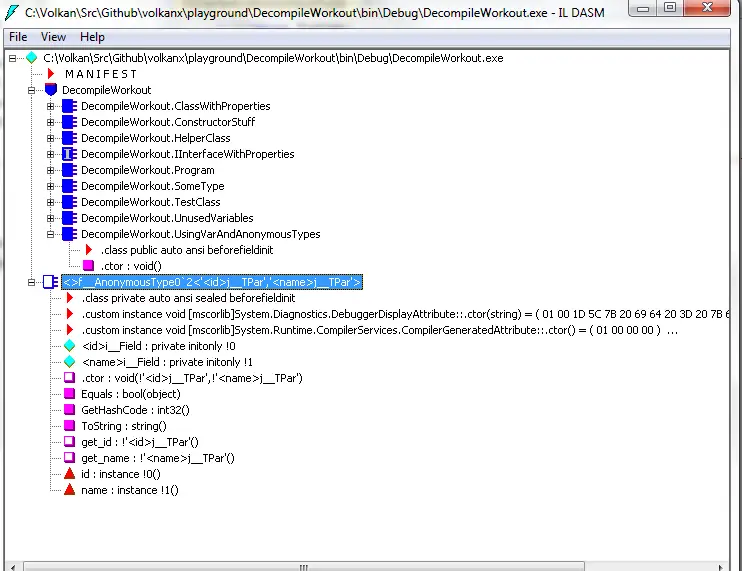
For the anonymous type the compiler created a class for us with a very user-friendly name: <>f__AnonymousType0`2. It also generated readonly private fields and only getters that means they are immutable and we cannot set those values once the object is initialized.
06. Async and await
Async/await helps asynchronous programming much easier for us. It’s hiding a ton of complexity and I think it makes sense to invest some time into investigating how it works to use it properly. First of all, marking a method async doesn’t make everything asynchronous automagically. If you don’t use await inside the function it will run synchronously (the compiler will generate a warning about it). When you call an async method the execution continues without blocking the main thread. If it’s not awaited it returns a Task
public async void DownloadImageAsync(string imageUrl, string localPath)
{
using (var webClient = new WebClient())
{
Task task = webClient.DownloadFileTaskAsync(imageUrl, localPath);
var hashCalculator = new SynchronousHashCalculator();
// Do some more work while download is running
await task;
using (var fs = new FileStream(localPath, FileMode.Open, FileAccess.Read))
{
byte[] testData = new byte[new FileInfo(localPath).Length];
int bytesRead = await fs.ReadAsync(testData, 0, testData.Length);
// Do something with testData
}
}
}
In this example, a file is downloaded asynchronously. The execution continues after the call has been made so we can do other unrelated work while the download is in progress. Only when we need the actual value, to open the file in this instance, we await the task. If we didn’t await we would try to access the file before it’s completely written and closed resulting in an exception.
One confusing aspect maybe calling await on the same line as in fs.ReadAsync in the above example. It looks like it’s synchronous as we are still waiting on the same line but the difference is the main thread is not blocked. If it’s a GUI-based application for exmaple it would still be responsive.
So let’s decompile the assembly to see how it works behind the scenes. This is one of the times I like having redundancy. Because Just Decompile failed to generate C# code for the class using async/await so I had to switch to ILSpy.
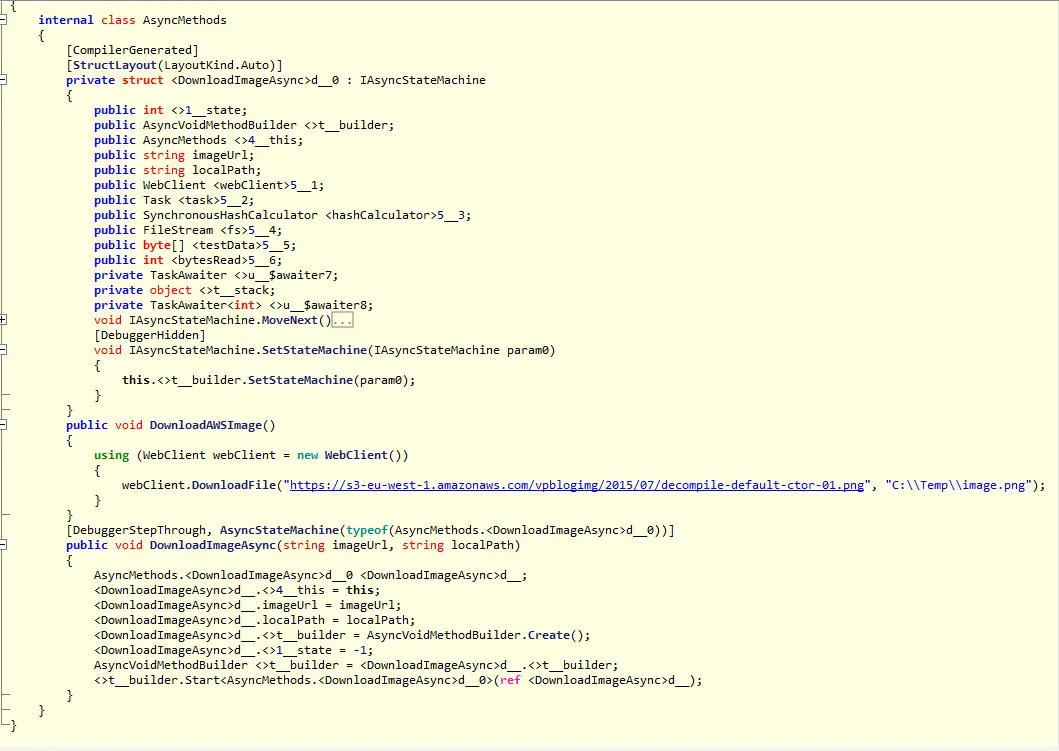
It generates a struct implementing IAsyncStateMachine interface. The “meaty” part is the MoveNext method:
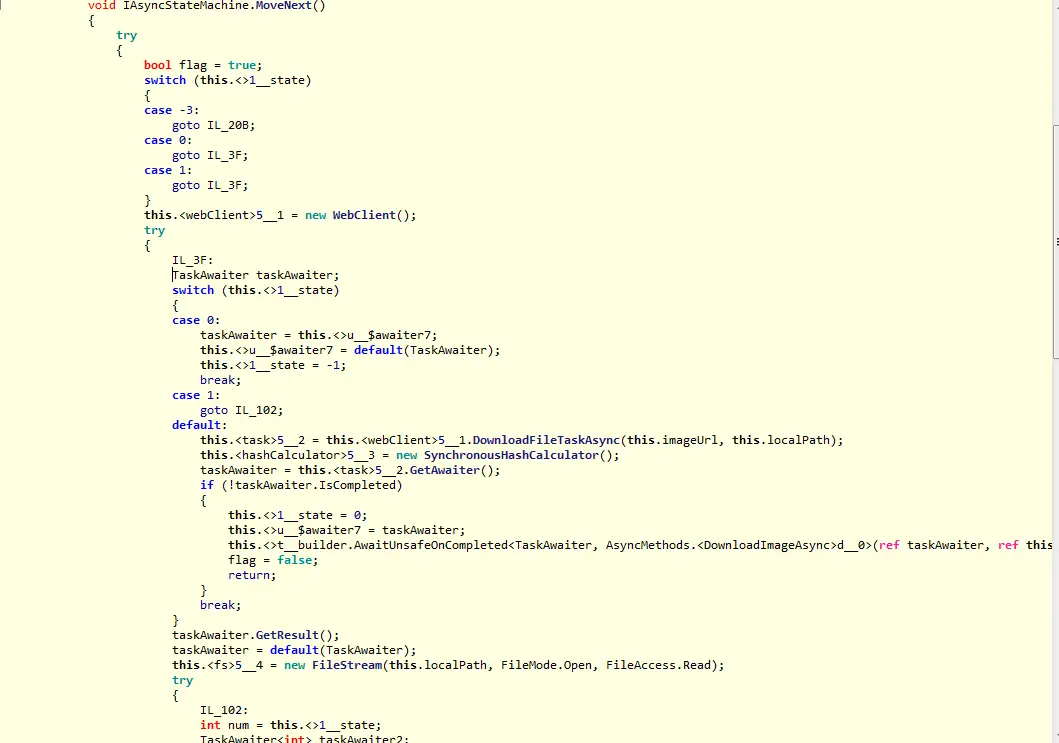
It’s very hard to read compiler-generated code but I think this part is interesting:
switch (this.<>1__state)
{
case 0:
taskAwaiter = this.<>u__$awaiter7;
this.<>u__$awaiter7 = default(TaskAwaiter);
this.<>1__state = -1;
break;
case 1:
goto IL_102;
default:
this.<task>5__2 = this.<webClient>5__1.DownloadFileTaskAsync(this.imageUrl, this.localPath);
this.<hashCalculator>5__3 = new SynchronousHashCalculator();
taskAwaiter = this.<task>5__2.GetAwaiter();
if (!taskAwaiter.IsCompleted)
{
this.<>1__state = 0;
this.<>u__$awaiter7 = taskAwaiter;
this.<>t__builder.AwaitUnsafeOnCompleted<TaskAwaiter, AsyncMethods.<DownloadImageAsync>d__0>(ref taskAwaiter, ref this);
flag = false;
return;
}
break;
}
taskAwaiter.GetResult();
taskAwaiter = default(TaskAwaiter);
If the task has not been completed it sets the state to 0 which then comes back to default so it goes back and forth until taskAwaiter.IsCompleted is true.
07. New C# 6.0 Features
C# 6.0 has just been released a few days ago. There aren’t many groundbreaking features as the team at Microsoft stated. Mostly the new features are shothand notations to make the code easier to read and write. I decided to have a look at the decompiled code of some of the new structs
Null-conditional operators
This is a great remedy to ease the neverending null-checks. For example in the code below
var people = new List<Person>();
var name = people.FirstOrDefault()?.FullName;
If the list is empty name will be null. If we didn’t have this operator it would throw an exception therefore we would have to do the null checks on our own. The decompiled code for the above block is like this:
private static void Main(string[] args)
{
string fullName;
Program.Person person = (new List<Program.Person>()).FirstOrDefault<Program.Person>();
if (person != null)
{
fullName = person.FullName;
}
else
{
fullName = null;
}
}
As we can see, the generated code is graciously carrying out the null check for us!
String interpolation
This is one of my favourites: Now we can simply place put the parameters directly inside a string instead of placeholders. Expanding on the example above, imagine the Person class is like this:
class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string FullName => $"{FirstName} {LastName}";
}
The decompiled code looks familiar though:
public string FullName
{
get
{
return string.Format("{0} {1}", this.FirstName, this.LastName);
}
}
This is exactly how I would do it if we didn’t have this new feature.
Auto-property initializers
We can set the default value for a property on the declaration line now, like this:
public string FirstName { get; set; } = "Volkan";
And the IL generated for the code is like this:
Decompiled code varies. Just Decompile doesn’t just displays the exact same statement as above. ILSpy on the other hand is closer to the IL:
public Person()
{
this.<FirstName>k__BackingField = "Volkan";
this.<BirthDate>k__BackingField = new DateTime(1966, 6, 6);
base..ctor();
}
So what it does is, in the constructor it sets the private backing field with this default value we assign.
Expression bodied members
We can now provide the body of the function as an expression following the declaration like this:
public int GetAge() => (int)((DateTime.Now - BirthDate).TotalDays / 365);
The decompiled code is not very fancy:
public int GetAge()
{
TimeSpan now = DateTime.Now - this.BirthDate;
return (int)(now.TotalDays / 365);
}
It simply puts the expression back in the body.
Index initializers
It’s a shorthand for index initialization such as
Dictionary<int, string> dict = new Dictionary<int, string>
{
[1] = "string1",
[2] = "string2",
[3] = "string3"
};
And the decompiled code is no different than what it is now:
Dictionary<int, string> dictionary = new Dictionary<int, string>();
dictionary[1] = "string1";
dictionary[2] = "string2";
dictionary[3] = "string3";
As I mentioned there is nothing fancy about the new features in terms of the generated IL but some of them will help save a lot of time for sure.
08. Compiler code optimization
It is interesting to see how decompilers use optimization on their own. Before I went into this I thought they would just reverse engineer whatever is in the assembly but turns out that’s not the case.
First, let’s have a look at the C# compiler’s behaviour. In Visual Studio, Optimize code flag can be found under Project Properties -> Debug menu
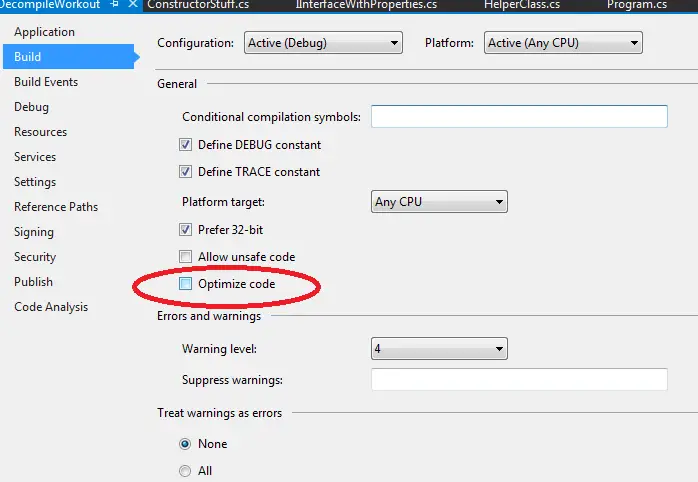
In order to test code optimization I created a dummy method like this:
public class UnusedVariables
{
public void VeryImportantMethod()
{
var testClass = new TestClass("some value");
TestClass testClass2 = null;
var x = "xyz";
var n = 123;
}
}
First I compiled it by default values:
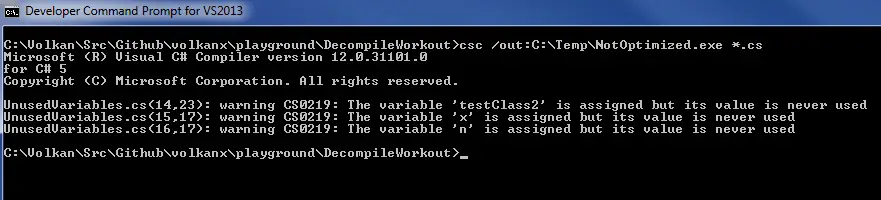
Then disassembled the output:
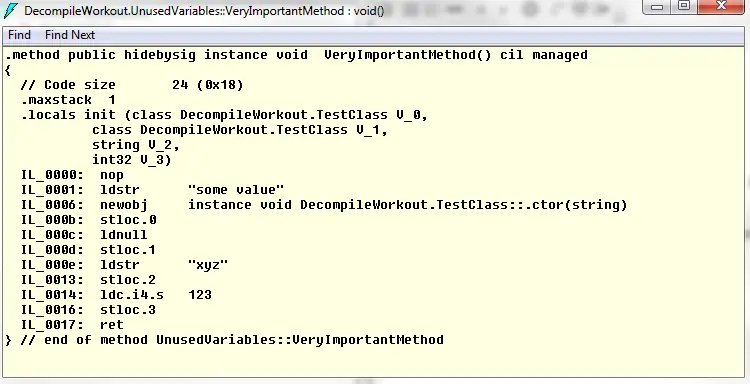
I’m no expert in reading IL code but it’s obvious in the locals section there are 2 TestClass instances, a string and a integer.
When I compiled it with the optimization option (/o):
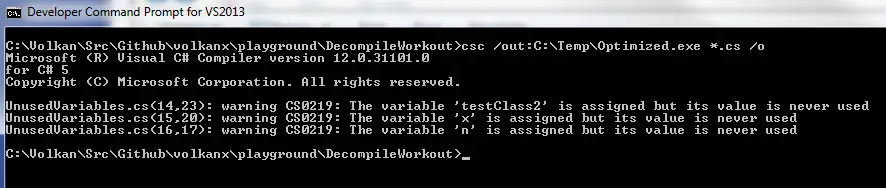
I got the following when disassembled:
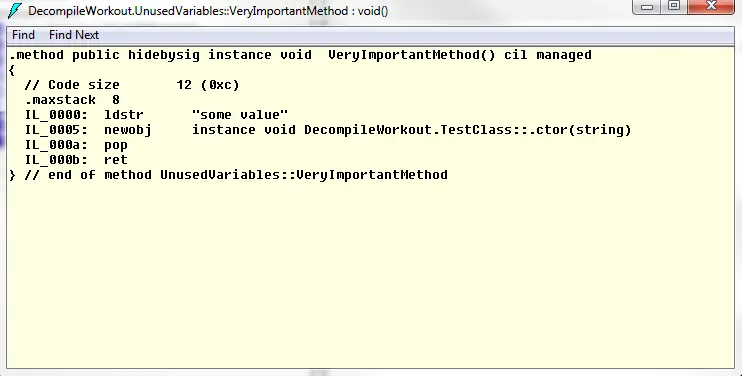
There’s no trace of the value types (string and the int). Also the TestClass instance with null value is gone. But the TestClass instance, which is created in the heap rather than the stack, is still there even though there is nothing referencing it. It’s interesting to see that difference.
When I decompiled both versions with ILSpy and JustDecompile unused local variables were removed all the time. Apparently they do their own optimization.
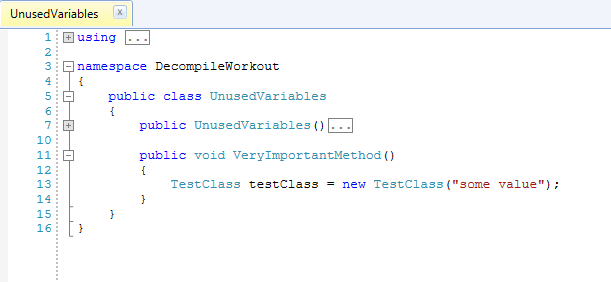
Conclusion
It was a fun exercise to investigate and see the actual generated code. It was helpful to understand better complex constructs like async/await and also helpful to see there’s nothing to fear about the new features of C# 6.0!
Resources
- CLR via C#, 4th Edition
- MSDN: var keyword
- MSDN: using statement
- ILDASM
- CodeProject Article: Async Await and the Generated StateMachine
- MSDN: Asynchronous Programming with Async and Await
- Blog post: Async compilation internals
- Stackexchange question: async+await == sync?
- Blog post: 7 C# 6.0 Features That Every ASP.NET Developer Should Know About
