
Graph Databases
Graph databases are getting more popular every day. I played around with it in the past but never covered it extensively. My goal is now to first cover the basics of graph databases (Neo4J in particular), cover Cypher (a SQL-Like Query Language for Neo4J) and build a full-blown project using these. So this will the first post in a multi-part series.
Neo4J is providing nice training materials. Also I’m currently enjoying active Safari Books Online and Pluralsight subscriptions so I thought it might be a good time to conduct a comprehensive research and go through all of these resources. So without further ado, here’s what I’ve gathered on Graph Databases:
Why Graph Databases
Main focus of graph databases is the relationships between objects. In a graph database, every object is represented with a node (aka a vertex in graph theory) and nodes are connected to each other with relationships (aka an edge).
Graph databases are especially powerful tools for heavily connected data such as social networks. When you try to model a complex real-world system you end up having a lot of entities and connections among them. At this point a traditional relational model starts to be sluggish and hard to maintain and this is where graph databases come to rescue..
Players
Turns out there are many implementations and it’s a broader concept as they have different attributes. You can check this Wikipedia article to see what I mean. As of this writing there were 41 different systems mentioned in the article. A few of the players in the field are:
- Neo4J: Most popular and one of the oldest in the field. My main focus will be on Neo4J throughout my research
- FlockDB: An open-source distributed graph database developed by Twitter. It’s much simpler than Neo4J as it focuses on specific problems only.
- Trinity: A research project from Microsoft. I wish it was released because probably it would come with native .NET clients and integration but looks like it’s dead already as there is activity since late 2012 on its page.
Popular Graph Models
There are three dominant graph models in the industry:
- The property graph
- Resource Description Framework (RDF) triples
- Hypergraphs
The Property Graph Model
- It contains nodes and relationships
- Nodes contain properties (key-value pairs)
- Relationships are named and directed, and always have a start and end node
- Relationships can also contain properties
- No prior modelling is needed but it helps to understand the domain. The advice is start with no schema requirements and enforce a schema as you get closer to production.
Basic concepts
As I will be using Neo4J, I decided to focus on the basic concepts of Neo4J databases (the current version I’m using is 2.1 and 2.2M03 which is still in beta)
- Nodes - Graph data records
- Relationships - Connect nodes. They must have a name and a direction. Sometimes direction has semantic value and sometimes the connection if bothways like a MARRIED_TO relationship. It doesn’t matter which way you define it both nodes are “married to” each other. But for example a “LOVES” relationship doesn’t have to be bothways so the direction matters.
- Properties - Named data values
- Labels - Introduced in v2.0 They are used to tag items like Book, Person etc. A node can have multiple labels.
Conclusion
Graph databases are on the rise as can be seen clearly from the chart (taken froom db-engines.com):
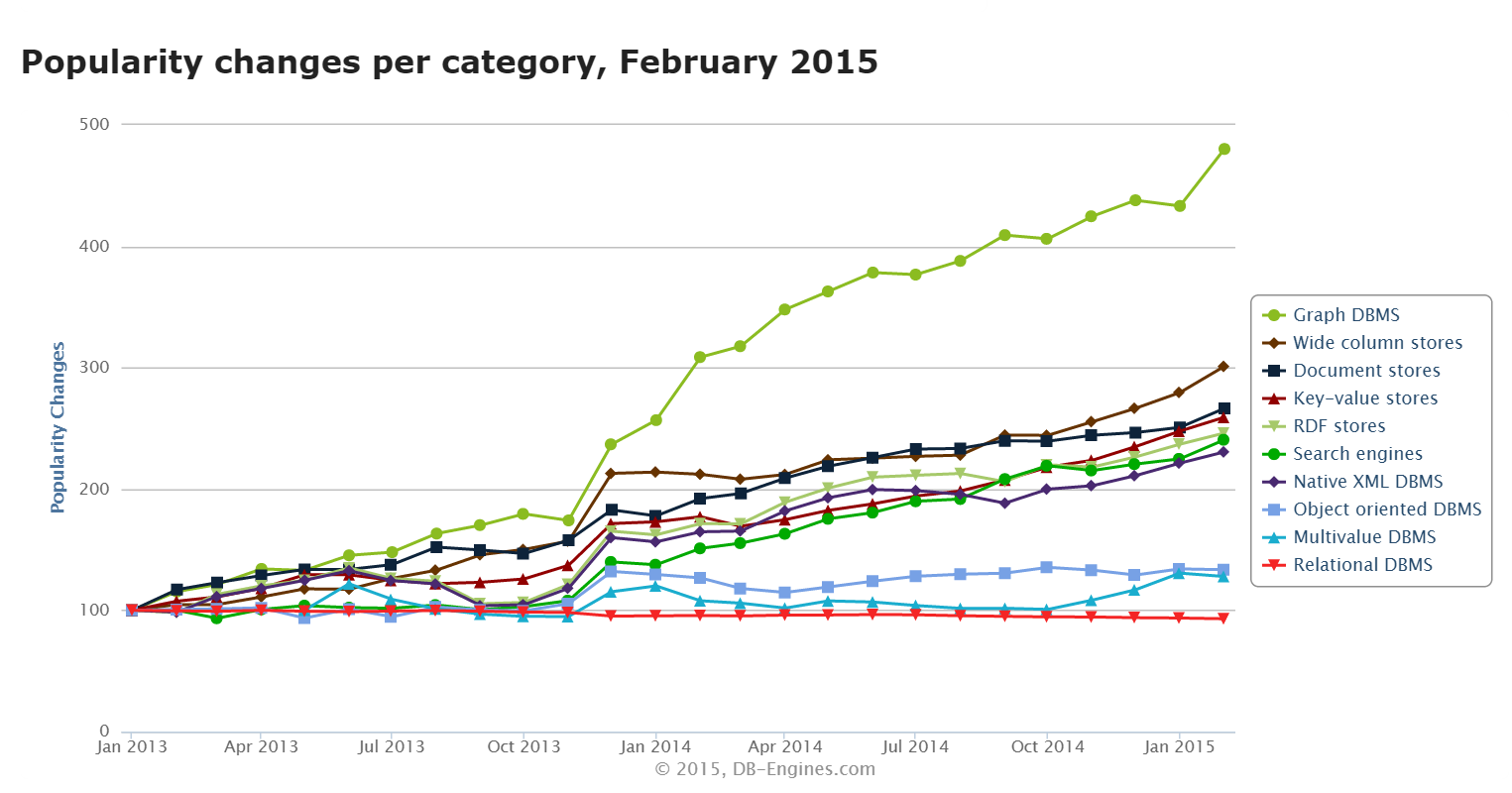
It feels very natural to model a database as a graph as they can handle relationships very well and in real-life there are many complex relationships in semi-structured data. So especially at the beginning starting without a schema and have your model and data mature over time makes perfect sense. So it is understandable why graph databases are gaining traction everyday.
In the next post I will delve into Cypher - the query language of Neo4J. What good is a database if you can’t run queries on it anyway, right? :-)