
An Apriori implementation
I was digging through some old projects and found out the Data Mining and Machine Learning projects I implemented. Instead of letting them gather dust(!) in the hard disk I decided to review and publish the source code. This will also give me a chance to revise my data mining knowledge. Let’s start with Apriori algorithm.
Apriori Algorithm
It is an algorithm to determine to most frequent items in a given collection. The term “frequent” is defined by a given threshold or “minimum support count”.
Implementation
The project is implemented in Java. It uses a Hashtable to keep count of itemsets in the database. The algorithm starts with finding the most frequent 1-item sets first. Then using the previous most frequent item list of item size k, it generates candidate item list of size k+1.
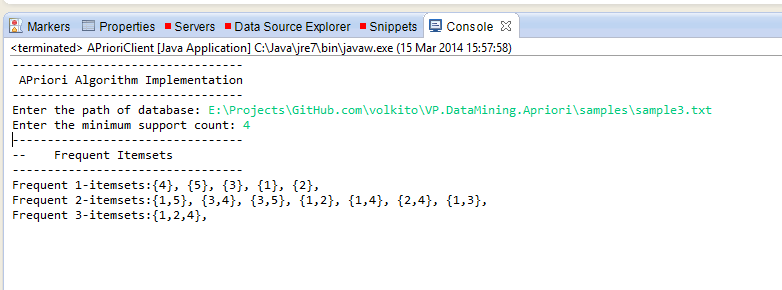
For example, for the sample data below and a threshold 4, 1,2,3,4,5 are all frequent 1-itemsets. From this list we generate a 2-item candidate list (all 10 combinations) and check if the subsets are also frequent. For 1-itemsets they are all frequent so they all pass pruning. Then we count the occurences of these candidates. Only 7 of them are equal to or greater than the threshold. From this list we generate our 3-item candidates. Such as 1,2 and 1,4 combined to generate 1,2,4. Then we count the occurrence of 3-itemsets and prune the results by checking all of its subsets.
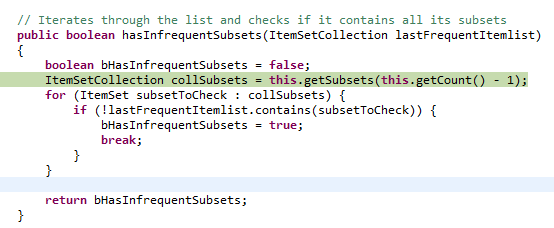
The idea of pruning is if the there are some infrequent subsets inside an itemset then the larger set cannot be frequent so it is removed from the candidate list. (1,2,3 is a candidate but as 2,3 is not a frequent 2-itemset it is removed from the candidate list) This process helps improve the performance of the algorithm as it reduced the number of iterations.
Output
1,3,4,5
1,2,4,5
1,2,4
1,3
3
1,5
1
3
1,3,5
4
1,2,4
2
1,2
3,4
3,5
1,3,4
2
3,5
1,2,3,4
Results:
Source Code
I created a public repository for the source code. You can check it out here if it tickles your fancy!